
阅读文档版本:
具体开发指南 Cangjie-LTS-1.0.3↗
在阅读 了解仓颉的语言规约时, 难免会涉及到一些仓颉的示例代码, 但 我们对仓颉并不熟悉, 所以可以用仓颉在线体验↗快速验证
有条件当然可以直接配置Canjie-SDK↗
博主在此之前, 基本只接触过C/C++语言, 对大多现代语言都没有了解, 所以在阅读过程中遇到相似的概念, 难免会与C/C++中的相似概念作类比, 见谅
此样式内容, 表示文档原文内容
类型
仓颉编程语言是一种 静态类型(statically typed) 语言: 大部分保证程序安全的类型检查发生在编译期
同时, 仓颉编程语言是一种 强类型(strongly typed) 语言: 每个表达式都有类型, 并且表达式的类型决定了它的取值空间和它支持的操作
静态类型和强类型机制可以帮助程序员在编译阶段发现大量由类型引发的程序错误
静态类型语言, 表示 代码的类型检查发生在编译期, 在编译期就需要确定好每个变量的实际类型, 即如果代码中存在类型的不匹配等错误, 会在编译期就报错
强类型语言, 说明 仓颉可能会禁止很多或许很常见的隐式类型转换
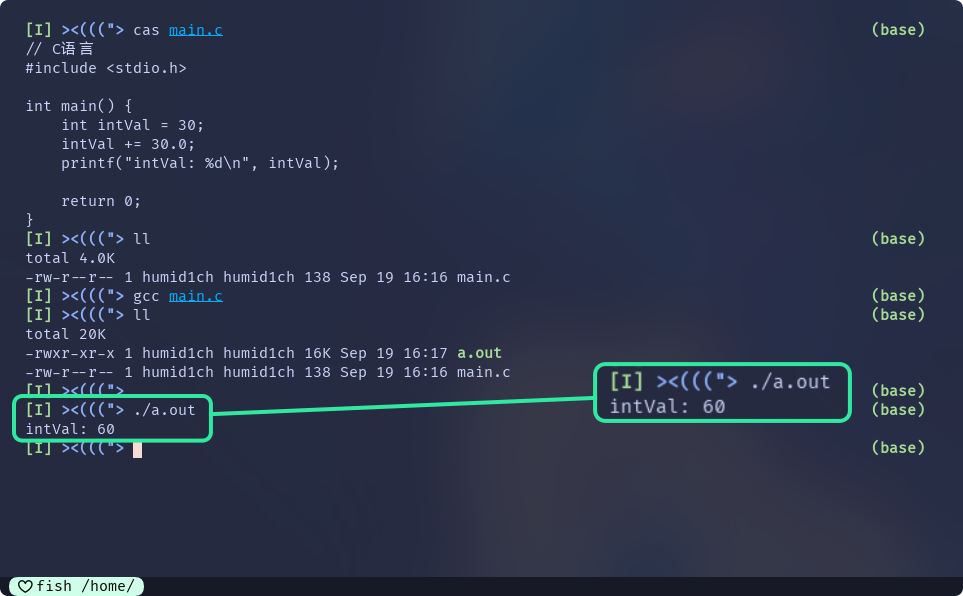
用C语言和仓颉举一个最简单的例子:
// C语言
#include <stdio.h>
int main() {
int intVal = 30;
intVal += 30.0;
printf("intVal: %d\n", intVal);
return 0;
}// Cangjie
main() {
var intVal = 30
intVal += 30.3
println(intVal)
return 0
}这两段代码, C语言是可以编译通过 并可以运行的:
但是, 仓颉就无法编译通过:
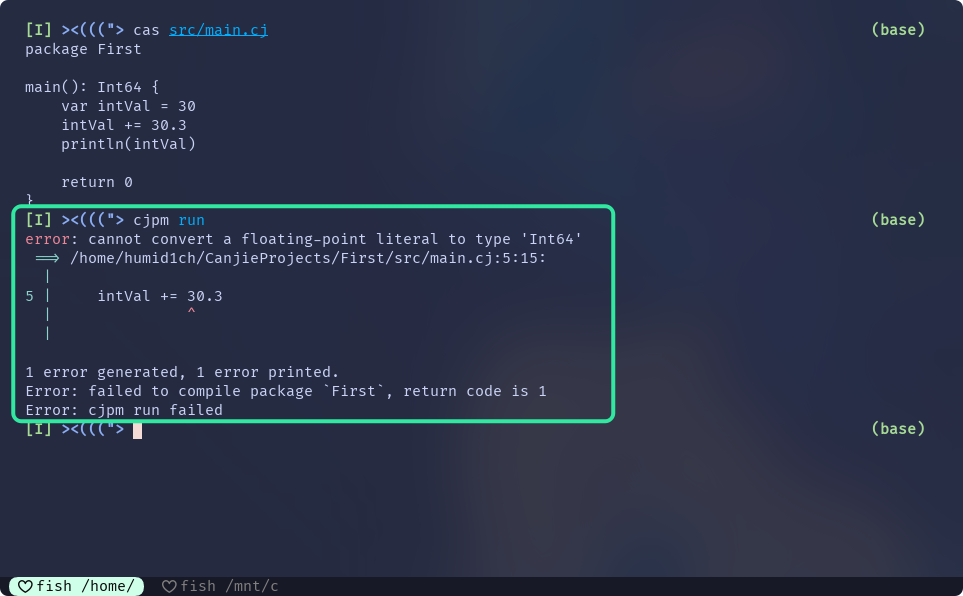
仓颉无法编译通过的原因是, 不能将浮点值隐式转换为Int64类型
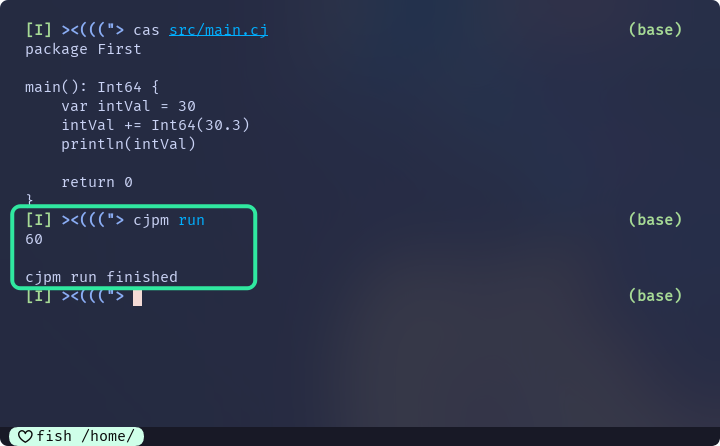
但是, 如果显式进行类型转换, 就可以:
main() {
var intVal = 30
intVal += Int64(30.3)
println(intVal)
return 0
}
文档中还提到, 仓颉每个表达式都有类型, 也就是说表达式也禁止隐式类型转换
就像, C/C++中你可以将表达式1 + 1当作true使用, 但仓颉中1 + 1不能被当作true, 只能使用布尔类型中的true和false表示真和假
可变类型 和 不可变类型
仓颉中的类型可分为两类: 不可变类型(immutable type)和可变类型(mutable type)
其中, 不可变类型包括数值类型(分为整数类型和浮点数类型)、
Rune类型、Bool类型、Unit类型、Nothing类型、String类型、元组(Tuple)类型、Range类型、函数(Function)类型、enum类型可变类型包括
Array类型、VArray类型、struct类型、class类型和interface类型不可变类型和可变类型的区别在于: 不可变类型的值, 其数据值一经初始化后就不会发生变化; 可变类型的值, 其数据值初始化后仍然有可以修改的方法
对于基本只接触过C/C++的我来说, 我想真心的发问 可变类型和不可变类型是什么?
不可变类型的值, 其数据值一经初始化后就不会发生变化?? 可变类型的值, 其数据值初始化后仍然有可以修改的方法??
在C/C++中, 对于一个普通变量, 定义好之后 可以随便修改这个变量的值啊? 难道仓颉不是吗?
经过了解, 发现还真不是, 而且不少现代语言中 都存在可变类型和不可变类型
不可变类型的值, 其数据值一经初始化后就不会发生变化
这表示, 不可变类型定义一个变量, 用一个值给变量初始化之后, 这个值就无法改变了:
如果你再给这个变量赋值, 本质上并不是用一个新值替换了这个变量中的旧值, 而是创建了一个新的同名变量存储了新值
这与C/C++不同, C/C++中定义一个变量之后, 如果对这个变量进行赋值等操作, 都是向这个变量的原内存空间 存入新的值, 变量的地址无论是实际上还是逻辑上, 都没有发生改变
而现代语言中, 这种不可变类型的变量, 如果给变量赋值, 事实上就是创建了一个新的同名变量存储新的值, 变量的地址从逻辑上是会发生变化的, 但现代语言基本不提供查看实际地址的操作, 要想查看地址可能会比较复杂, 所以一般无法观测
而可变类型, 就可以看作C/C++中的普通变量, 对象的内存是不改变的, 只是修改值
不可变类型
数值类型
数值类型包括整数类型与浮点数类型, 分别用于表示整数和浮点数
整数类型包含有符号(signed)整数类型和无符号(unsigned)整数类型
其中, 有符号整数类型包括
Int8、Int16、Int32、Int64和IntNative, 分别用于表示编码长度为8-bit、16-bit、32-bit、64-bit和平台相关大小的有符号整数值的类型;无符号整数类型包括
UInt8、UInt16、UInt32、UInt64和UIntNative, 分别用于表示编码长度为8-bit、16-bit、32-bit、64-bit和平台相关大小的无符号整数值的类型浮点数类型包括
Float16、Float32和Float64, 分别用于表示编码长度为16-bit、32-bit和64-bit的浮点数的类型
IntNative/UIntNative的长度与当前系统的位宽一致
仓颉语言中 整型和浮点型属于不可变类型
| 类型 | 范围 |
|---|---|
Int8 | −27 ∼ 27−1 (-128 to 127) |
Int16 | −215 ∼ 215−1 (-32768 to 32767) |
Int32 | −231 ∼ 231−1 (-2147483648 to 2147483647) |
Int64 | −263 ∼ 263−1 (-9223372036854775808 to 9223372036854775807) |
IntNative | 平台相关 |
UInt8 | 0 ∼ 28−1 (0 to 255) |
UInt16 | 0 ∼ 215−1 (0 to 65535) |
UInt32 | 0 ∼ 231−1 (0 to 4294967295) |
UInt64 | 0 ∼ 263−1 (0 to 18446744073709551615) |
UIntNative | 平台相关 |
Float16 | 详情见 IEEE754 Binary16 格式 |
Float32 | 详情见 IEEE754 Binary32 格式 |
Float64 | 详情见 IEEE754 Binary64 格式 |
Byte类型作为UInt8的类型别名,Byte与UInt8完全等价Int/UInt类型分别作为Int64/UInt64的类型别名,Int与Int64完全等价,UInt与UInt64完全等价
除了表中的类型, 还可以用Byte替代UInt, 用Int代替Int64, 用UInt代替UInt64
数值类型字面量
详细的表述, 在阅读仓颉文档的第一篇文章↗中 有涉及仓颉中的整型字面量 和 浮点类型字面量
浮点类型量中有几个特殊的值需要注意: 正无穷(
POSITIVE_INFINITY), 负无穷(NEGATIVE_INFINITY), Not a Number(NaN), 正0(+0.0), 负0(-0.0)其中, 无穷表示操作结果超出了表示范围, 例如将两个很大的浮点数相乘, 或将一个非零浮点数除以浮点零时, 其结果都是无穷, 无穷的符号由操作数的符号决定, 符合”正负得负, 负负得正”的规律
NaN表示既不是实数也不是无穷的情况, 例如计算正无穷乘以0的结果就是NaN
仓颉编程语言中的浮点小数类型的最小正值为非正规浮点小数 (subnormal floating point number)
对于
Float32类型最小可表示的正浮点数为 2−149, 大约为1.4e-45; 而最大值可表示的数为 (2 − 2−23)×2127, 大约为3.40282e38对于
Float64类型最小可表示的正浮点数为 2−1074, 大约为4.9e-324; 而最大可表示的数为 (2 − 2−52)×21023, 大约为1.79769e308
当非 0 的浮点小数字面值因过小或者过大而舍入得到 0 或者无穷, 那么编译器会告警
数值类型支持的操作符
数值类型支持的操作符包括: 算术操作符、位操作符、关系操作符、自增(减)操作符、一元负号操作符和(复合)赋值操作符
其中浮点类型不支持位操作符
算术操作符包括加(
+)、减(-)、乘(*)、除(/)、取余(%)、取幂(**)默认算术操作符没有被重载的情况下, 要求算术操作符的两个操作数的类型必须相同, 如果要将两个不同类型的操作数进行操作, 必须先进行强制类型转换
这一句表述, 其实也是 仓颉语言是一种强类型语言的一种体现
在算术操作符没有重载的情况下, 即 操作符功能是默认的情况下, 操作符两边的操作数的类型要一致
这里的一致, 不仅仅是只 整型 或 浮点型, 还有具体类型也要一致, 即 如果一个操作数为Int32则 另一个操作数也必须是Int32
下面这段代码, 就会出现问题:
main() {
var int32Val: Int32 = 30
var int64Val: Int64 = 30
var intVal = int32Val + int64Val
return 0
}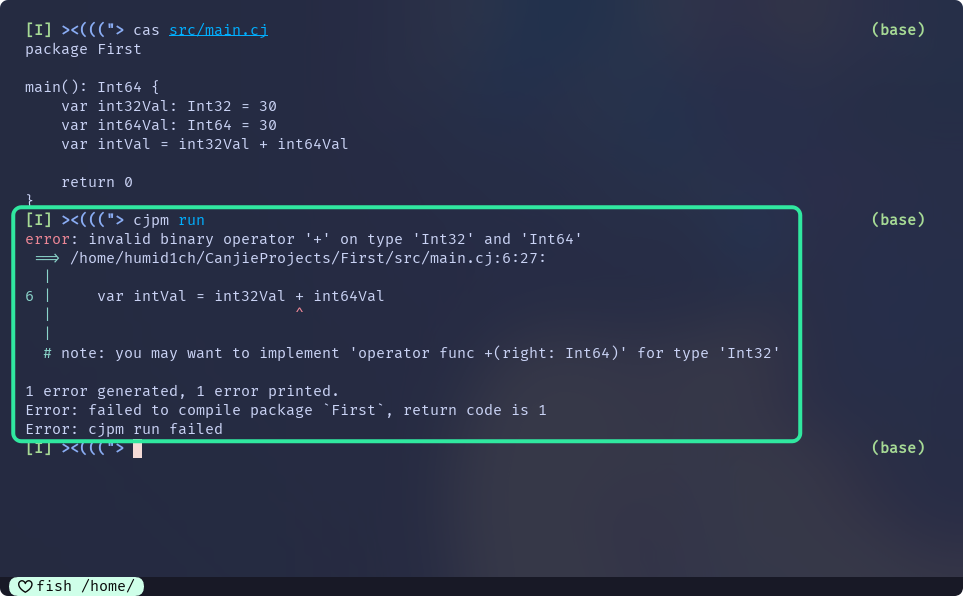
错误: 二元操作符+的操作数为Int32和Int64两种类型, 不合法
位操作符 包括位求反(
!)、左移(<<)、右移(>>)、位与(&)、位异或(^)、位或(|)
关系操作符包括小于(
<)、大于(>)、小于等于(<=)、大于等于(>=)、相等(==)、不等(!=), 关系表达式的结果是一个Bool类型的值(true或false)
仓颉中关系表达式的结果是Bool类型的, 可以作为判断条件使用
自增(减)操作符包括自增(
++)和自减(--), 可看做是一种特殊的赋值操作符(见下), 用于实现将变量值加(减)1自增(减)操作符只能作为后缀操作符使用, 且只能作用于整数类型可变变量, 因为不可变变量和整数字面量的值不允许修改
与C/C++中的++和--不同, 仓颉语言中的++和--只能后置
仓颉中的++和--只能操作 整型可变变量, 即var修饰定义的整型变量
文章提到, 更详细的说明, 在关于表达式的内容中有介绍
一元负号操作符使用
-表示, 结果是对其操作数取负
(复合)赋值操作符包括赋值(
=)和复合赋值操作(op=), 其中op可以是算术操作符、逻辑操作符和位操作符中的任意二元操作符(复合)赋值操作可以实现一个值为数值类型的表达式到数值类型变量的赋值
浮点数类型支持的操作符
浮点类型支持的操作包括(注意没有位操作): 算术操作、关系操作、自增(减)操作、一元正(负)号操作、条件操作和(复合)赋值操作
浮点数的计算可能使用与其本身类型不同精度的操作
浮点操作中有几种特殊情况需要注意: 在关系表达式中, 如果有操作数的值为
NaN, 则表达式的结果为false, 除了NaN != x与x != NaN的结果为true(x可以是包括NaN在内的任意浮点数)
浮点操作中, 大多与整形操作一致, 但浮点类型数据中存在NaN
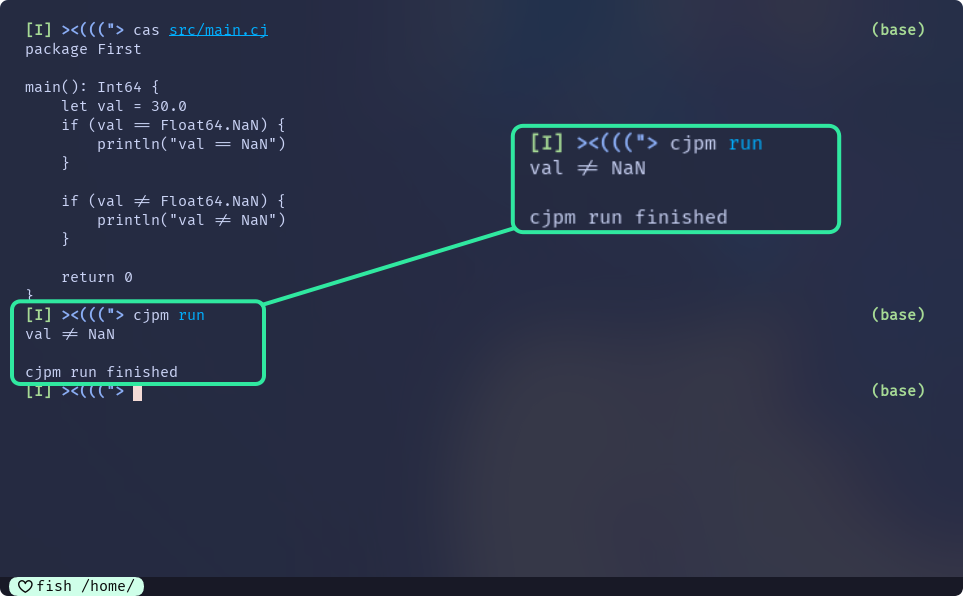
所以, 关系表达式中存在值为NaN的变量的话, 有特定的结果计算方式:
main() {
let val = 30.0
if (val == Float64.NaN) {
println("val == NaN")
}
if (val != Float64.NaN) {
println("val != NaN")
}
return 0
}
仓颉在std.math包中, 提供了接口, 可以获取不同浮点精度的NaN
Rune类型
仓颉编程语言使用
Rune类型表示Unicode code point这些值可分为可打印字符、非打印字符(不可显示的字符, 如控制符)、特殊字符(如单引号和反斜线)
Rune类型, 就是仓颉中的单字符类型
Rune类型的值是Unicode字符集中的字符, Rune类型代表一个完整的Unicode码位
Unicode字符集中, 除了基础的ASCII码符号, 还有中文和emoji表情等, 所以Rune占用的大小肯定不是1字节
关于Rune字面量可以阅读上一篇文章中相关内容↗
Rune类型的字面量由一对单引号和字符组成, 如:'S' '5' ' '非打印和特殊的字符型字面量使用转义字符(
\)定义:
escape character character \0Empty character \\backslash \\bBackspace \fWriter \nnewline \rEnter \tHorizontal tab \vVertical tab \’single quotation mark ’\"double quotation marks "\u{X}Any Unicode code point, where Xis a 1-8 digit hexadecimal number
Rune类型仅支持关系操作符(根据Unicode code point编码进行比较)main() { 'A'=='A' // result: true 'A'!='A' // result: false 'A'<'a' // result: true 'A'<='A' // result: true 'A'>'a' // result: false 'A'>='A' // result: true return 0 }
C/C++语言中, 用char类型表示单个字符, char本质是整型, 所以可以进行整型的算术运算
而仓颉中, 明确Rune不可以进行非关系操作符的任何运算
Bool类型
Bool类型字面量(Bool Literal)
Bool类型的字面量只有两个:true和false, 分别表示”真”和”假”
Bool类型支持的操作仓颉编程语言不支持数值类型与
Bool之间的类型转换, 也禁止非Bool的值作为Bool值来使用, 否则会报编译错误
Bool类型支持的操作有: 赋值操作、部分复合赋值操作(&&=,||=)、部分关系操作(==,!=)和所有逻辑操作(!,&&,||)
仓颉语言中, 禁止整型和浮点型与布尔类型之间的转换, 也禁止其他非布尔值作为布尔值使用
在C/C++语言中, 整型和浮点型数据是可以直接作为布尔表达式表示真假的, 非0即为真, 仓颉显然禁止掉了这种使用
经过测试, 仓颉的Bool类型甚至没有提供直接使用类型名强制类型转换的功能, 即 没有办法通过Bool(value)的方式将值强制转换到Bool类型
仓颉布尔类型数据支持的操作:
main() {
let bool1: Bool = true
var bool2: Bool = false
bool2 = true // assignment
bool2 &&= bool1 // bool2=true
bool2 ||= bool1 // bool2=true
true == false // return false
true != false // return true
!false // logical NOT, return true
true && false // logical AND, return false
false || false // logical OR, return false
return 0
}Unit类型
Unit类型只有一个值:()
仓颉的语言规约-类型文档中, 对Unit只有这一句描述
而在开发指南中是这样描述的:
对于那些只关心副作用而不关心值的表达式, 它们的类型是
Unit例如,
Unit
Unit类型只有一个值, 也是它的字面量:()除了赋值、判等和判不等外,
Unit类型不支持其他操作
思来想去, 感觉可以把Unit类型类比为C/C++中的void, 是一个有字面量, 且字面量只能为()的void
因为仓颉语言是强类型语言, 所以这里Unit类型的赋值、判等和判不等操作, 应该是Unit类型之间的使用
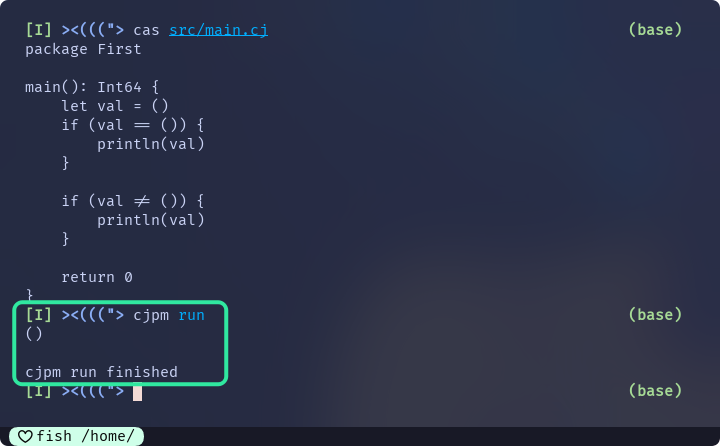
main() {
let val = ()
if (val == ()) {
println(val)
}
if (val != ()) {
println(val)
}
return 0
}
Nothing类型
Nothing是一种特殊的类型, 它不包含任何值, 并且Nothing是所有类型的子类型
Nothing暗示着死代码, 例如如果变量为Nothing类型, 则其永远不会被使用, 因此也不需要为其创建内存;如果函数调用的某个参数为
Nothing类型, 则该参数后面的参数不会被求值, 函数调用本身也不会被执行;如果 块内 某条表达式是
Nothing类型, 则其后的所有表达式和声明均不会被执行到仓颉编译器会对检测到的死代码进行编译告警
Nothing, 在C/C++中 没有一个类型可以类比为Nothing
但从描述来看: 如果 块内 某条表达式是Nothing类型, 则其后的所有表达式和声明均不会被执行到
return语句、continue和break好像与 仓颉中Nothing类型的表达式的作用有些相似
代码块中:
return可以直接返回整个函数, 之后的表达式都不会执行break可以直接结束循环, 循环体之后的表达式也不会被执行continue可以直接跳过本趟循环, 直接进入下一趟循环
String类型
仓颉编程语言使用
String表示字符串类型, 用于表达文本数据由一串 Unicode 字符组合而成
字符串字面量可以分为三类: 单行字符串字面量, 多行字符串字面量, 多行原始字符串字面量
关于字符串字面量, 前一篇文章中的相关内容↗已经阅读过了
插值字符串
插值字符串 是一种包含一个或多个插值表达式的字符串字面量(不适用于多行原始字符串字面量)
当插值字符串解析为结果字符串时, 每个插值表达式所在位置会被对应表达式的结果替换
每个插值表达式必须用
{}括号包起来, 并加上$前缀, 大括号中支持和 块 中一样的表达式声明序列, 但不能为空多行字符串中的插值表达式支持换行
插值字符串, 应该是C++开发者心心念念了很久的东西了, 但即使是C++最新的标准, 它还没有呈上来
这应该是现代语言非常常用的一种字符串字面量
main() {
let obj = "apples"
let count = 10
let interps1 = "There are ${count * count} ${obj}."
println(interps1)
return 0
}"There are ${count * count} ${obj}."就是一种插值字符串, ${count * count}和${obj}都是插值表达式
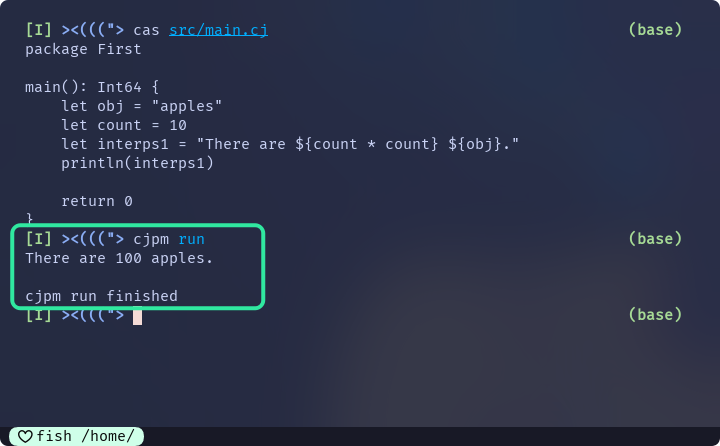
如果字符串中的
$符号后面没有{, 则当成普通$符号处理如果在
$前添加了转义字符\, 那么无论$符号后面是不是{, 都不会被当成插值表达式处理插值表达式也支持自定义类型, 只要该类型满足
ToStringinterface 约束
插值字符串中的插值表达式, 都会被转换为对应的字符串
插值表达式的{}中应该支持, 任何完整的、类型存在接口toString的表达式
Tuple类型
仓颉编程语言中元组(
Tuple)类型是一个由多种不同类型组合而成的不可变(immutable)类型, 使用(Type1, Type2, ..., TypeN)表示, 其中N代表元组的维度关于元组类型, 说明如下:
Type1到TypeN可以是任意类型(要求 N 不小于 2, 即Tuple至少是二元的)对于元组的每一维度, 例如第 K 维, 可以存放任何
TypeK子类型的实例当
(Type1, Type2, ..., TypeN)中的Type1到TypeN均支持使用==进行值判等(使用!=进行值判不等)时, 此Tuple类型才支持使用==进行值判等(使用!=进行值判不等);否则, 此
Tuple类型不支持==和!=(如果使用==和!=, 编译报错)两个同类型的
Tuple实例相等, 当且仅当相同位置(index)的元素全部相等(意味着它们的长度相等)
元组是大多语言都拥有的一个概念
仓颉的Tuple元组可以类比C++11标准提出提出std::tuple
元组字面量
不过, 仓颉中并不存在Tuple这个关键字, 也意味着仓颉的元组类型并不使用关键字
元组字面量使用格式
(expr1, expr2, ... , exprN)表示, 其中多个表达式之间使用逗号分隔, 并且每个表达式可以拥有不同的类型
仓颉中元组字面量就像这样:(1, 2, 3, "one_two_three"), 对应的类型就是(Int64, Int64, Int64, String)
即, 类似(type1, type2, ..., typeN)这样的格式作为元组的类型
使用元组做解构
元组也可以用来对另一个元组值进行解构: 将一个元组中不同位置处的元素分别绑定到不同的变量
func multiValues(a: Int32, b: Int32): (Int32, Int32) { return (a + b, a - b) // The type of the return value of the function multiValues is (Int32, Int32). } main() { var (x, y) = multiValues(8,24) // Define an anonymous tuple who has two elements, i.e., x and y. print("${x}") // output: 32 print("${y}") // output: -16 return 0 }
按照文档中的例子:
函数multiValues会返回一个(Int32, Int32)类型的元组
main()函数中, 执行var (x, y) = multiValues(8, 24), 将返回的元组解构到两个变量中
最终的结果, x被赋值为32, y被赋值为-16, 即为multiValues(8, 24)返回的元组(8+24, 8-24)的两个元素
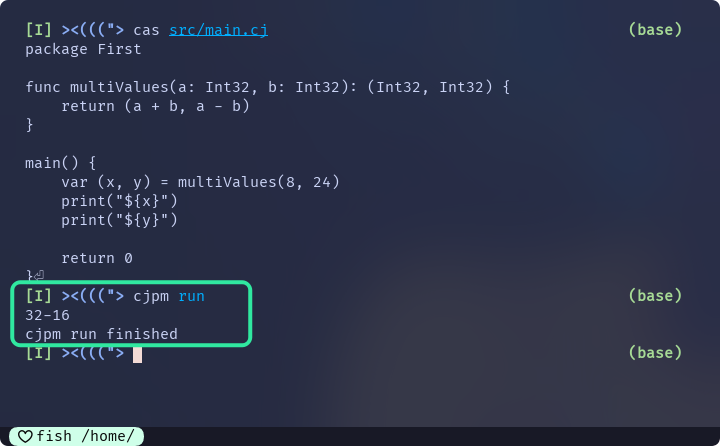
类似var (x, y)的方式, 是仓颉中的多变量声明的一种方式
在上面的示例中, 用于元组的解构赋值
如果只是要声明变量, 而不是解构元组, 就需要指明变量类型:
var (x, y): (Int64, Int64)元组的下标访问
元组支持通过
tupleName[index]的方式访问其中某个具体位置的元素(index表示从0开始的下标, 并且只能是一个Int64类型的字面量)
元组中元素的访问, 可以通过下标访问, 范围是[0, 1, ...]
重点是, 下标只能是Int64类型的字面量, 不能是任何变量
即:
let tuple = (1, 2)
tuple[0] // √
let index = 0
tuple[index] // ×定义元组类型的变量
在定义元组类型的变量时, 可以省略类型标注, 由编译器根据程序上下文推断出具体的类型
let tuplePIE = (3.14, "PIE") // The type of tuplePIE is inferred to be (Float64, String). var pointOne = (2.4, 3.5) // The type of pointOne is inferred to be (Float64, Float64). var pointTwo = (2, 3, 4) // The type of pointTwo is inferred to be (Int64, Int64, Int64). var pointThree = ((2, 3), 4) // The type of pointThree is inferred to be ((Int64, Int64), Int64).
除了省略类型让编译器自动推断外, 肯定要先了解不省略的定义方式:
let tuplePIE: (Float64, String) = (3.14, "PIE")
var pointOne: (Float64, Float64) = (2.4, 3.5)
var pointTwo: (Int64, Int64, Int64) = (2, 3, 4)
var pointThree: ((Int64, Int64), Int64) = ((2, 3), 4)因为元组的元素可以是任意类型的, 所以也可以元组套元组
Range类型
仓颉编程语言使用
Range<T>表示Range类型, 并要求T只能实例化为实现了Comparableinterface 和Countableinterface 的类型
Range又是一个C/C++中没有的一个类型, Python中倒是有range但只限于整型
仓颉中, Range是一个泛型类型, 但T必须要要实例化有两个接口:Comparable和Countable
这两个接口:
Comparable, 该接口表示比较运算, 等于、不等于、小于、大于、小于等于、大于等于接口的集合体Countable, 该接口表示类型可数, 可数类型的每一个实例在逻辑上都位于一个数轴上, 对应一个整数位置, 并且可以通过从这个位置”移动”一定的步数来得到其他的该类型实例
具体阅读到相关位置再做了解吧
Range类型用于表示一个拥有固定步长的序列, 并且是一个不可变(immutable)类型每个
Range<T>类型的实例都会包含start、end和step值其中,
start和end分别表示序列的起始值和终止值,step表示序列中前后两个元素之间的差值
Range类型支持使用==进行判等(使用!=进行判不等), 两个相同类型的 Range 实例相等: 当且仅当它们同时为”左闭右开”或”左闭右闭”, 并且它们的start值、end值和step值均对应相等
Range序列中, 每个元素之间的间隔都是相等的
类似:[0, 2, 4, 6, 8]或[0, 1, 2, 3, 4]
而不是:[0, 1, 2, 4, 5, 6]或[0, 2, 3, 4, 6, 8]
创建Range实例
存在两种
Range操作符:..和..=, 分别用于创建”左闭右开”和”左闭右闭”的Range实例它们的使用方式分别为
start..end:step和start..=end:step(其中start、end和step均是表达式)关于这两种表达式, 说明如下
要求
start和end的类型相同,step的类型为Int64表达式
start..end:step中,当
step > 0且start >= end, 或者step < 0且start <= end时,start..end:step返回一个空Range实例(不包含任何元素的空序列);如果
start..end:step的结果是非空Range实例, 则Range实例中元素的个数等于(end-start)/step向上取整(即大于等于(end-start)/step的最小整数)表达式
start..=end:step中, 当step > 0且start > end, 或者step < 0且start < end时,start..=end:step返回一个空Range实例; 如果start..=end:step的结果是非空Range实例, 则Range实例中元素的个数等于((end-start)/step)+1向下取整(即小于等于((end-start)/step)+1的最大整数)let range1 = 0..10:1 // Define an half-open range [0,10) (with step = 1) which contains 0, 1, 2, 3, 4, 5, 6, 7, 8 and 9. let range2 = 0..=10:2 // Define a closed range [0,10] (with step = 2) which contains 0, 2, 4, 6, 8 and 10. let range3 = 10..0:-2 // Define an half-open range [10,0) (with step = -2) which contains 10, 8, 6, 4 and 2. let range4 = 10..=0:-1 // Define a closed range [10,0] (with step = -1) which contains 10, 9, 8, 7, 6, 5, 4, 3, 2, 1 and 0. let range5 = 10..0:1 // Define an empty range. let range6 = 0..0:1 // Define an empty range. let range7 = 0..=0:1 // Define a closed range [0,0] (with step = 1) which only contains 0. let range8 = 0..=10:-1 // Define an empty range.表达式
start..end:step和start..=end:step中,step的值不能等于0let range9 = 0..10: 0 // error: the value of the step should not be zero. let range10 = 0..=10: 0 // error: the value of the step should not be zero.除了下节提到的
Range<Int64>类型的实例用在下标操作符[]中时可以省略start或end外, 其他场景下,start和end均是必选的, 只有step是可选的(默认step=1)let range11 = 1..10 // Define an half-open range [1, 10) with step = 1. let range12 = 1..=10 // Define a closed range [1, 10] with step = 1. let range13 = ..10 // error: the start value is required. let range14 = 1.. // error: the end value is required. let range15 = .. // error: the start and end value are required.
Range类型的使用
Range类型的表达式主要用在for-in表达式中, 以及作为下标用于截取片段需要注意的是:
- 当
Range<Int64>类型的实例用在下标操作符[]中时,start和end均是可选的- 它们的值由使用的上下文决定: 在自定义类型上重载下标操作符
[]且参数类型是Range<Int64>时, 使用过程中省略start时start的值等于0, 省略end时end的值等于Int64的最大值
“Range类型的表达式主要用在for-in表达式中, 以及作为下标用于截取片段”
for-in表达式的部分具体阅读到地方在具体了解
不过, Range可以作为下标用于截取片段
那么就意味着, Range可以出现在[]操作符中
结合文档的内容, 就会出现这几种合法用法:
obj[..end]
obj[start..]
obj[start..end]
obj[start..end:1]且经测试, 在仓颉标准库提供的Array和ArrayList等类型中, Range作为下标用于截取片段时, step只能为1
且, 即 如果使用..=的形式且不指定end, 会抛异常
以及, 如果start或end被省略, step禁止被显式指定, 会出现语法错误

定义Range类型变量
在定义
Range<T>类型的变量时, 可以显式添加类型标注, 也可以省略类型标注(此时由编译器根据程序上下文推断)let range16: Range<Int64> = 0..10 // Define an half-open range [0,10) with step = 1 let range17: Range<Int64> = -10..10:2 // Define an half-open range [-10,10) with step = 2 let range18 = 0..=10 // Define a closed range [0,10] with step = 1 let range19 = -10..=10:2 // Define a closed range [-10,10] with step = 2
Function类型
函数类型(function type)表示一个具体函数的类型, 它同样是
immutable的参数类型列表
parameterTypes和返回类型type使用->连接其中, 参数类型列表的一对
()是必选的,()内可以包含 0 个或多个类型(多个类型使用,分隔):() -> Int32 () -> Unit (Float32) -> Int32 (Int32, Int32, Float32) -> Int32 (Int32, Int32, Float32) -> (Int32, Int32) (Int32, Int32, Float32) -> Unit
仓颉中明确说明了函数的类型是这样的格式:(参数列表) -> 返回值类型
而仓颉中的函数定义则是:
func 函数名(参数列表): 返回值类型 {}仓颉编程语言中, 函数是一等公民(first-class citizens), 意味着函数可以作为其他函数的参数, 可以作为其他函数的返回值, 也可以直接赋值给变量
函数是一等公民, 可以作为其他函数的参数, 这时函数的具体类型就派上了用场
可以作为其他函数的返回值, 也就可以实现生产、定制函数的功能, 以及闭包
函数类型不支持使用
==(!=)进行判等(判不等)
enum类型
enum类型是一种immutable类型, 用于将一组相关的值(称为constructor)组织在一起声明为
enum类型的值, 其在任何时刻只能取enum类型定义中的某个constructor
枚举类型, C/C++中也有枚举类型, 但是仓颉中的枚举是现代语言中常见的枚举
定义enum类型
定义
enum类型的语法为:enumDefinition : enumModifier? 'enum' identifier typeParameters? ('<:' superInterfaces)? genericConstraints? '{' enumBody '}' ; enumBody : '|'? caseBody ('|' caseBody)* (functionDefinition | operatorFunctionDefinition | propertyDefinition | macroExpression)* ; caseBody : identifier ('(' type (',' type)* ')')? ;其中
enumModifier是enum类型的修饰符(即public),enum是关键字,identifier是enum类型的名字,typeParameters和genericConstraints分别是类型变元列表和类型变元的约束
enumBody中可以定义若干caseBody(即constructor), 每个constructor可以没有参数, 也可以有一组不同类型的参数, 多个constructor之间使用|分隔, 第一个constructor之前可以存在一个可选的|
caseBody后可以定义enum的其它成员, 包含成员函数、操作符重载函数、成员属性
C/C++中的枚举, 与现代语言中的枚举一般会存在很大的不同
以仓颉中的枚举类型为例, 按照文档中的说明, 仓颉的枚举类型是可以携带参数的, 且枚举类型内部还可以实现成员函数、成员属性等
enum TimeUnit1 {
Year | Month | Day | Hour
}
enum TimeUnit2 {
| Year(Float32)
| Month(Float32, Float32)
| Day(Float32, Float32, Float32)
| Hour(Float32, Float32, Float32, Float32)
}
enum TimeUnit3<T1, T2> {
| Year(T1)
| Month(T1, T2)
| Day(T1, T2, T2)
| Hour(T1, T2, T2, T2)
}关于
enum类型, 需要注意的是:
enum类型只能定义在top-level, 即 顶层作用域不支持空括号无参的
constructor定义, 且无参constructor的类型为被定义的enum类型本身, 不视作函数类型有参的
constructor具有函数类型, 但不能作为一等公民使用:enum E { | mkE // OK. The type of mkE is E but not () -> E. | mkE() // Syntax error. } enum E1 { | A } let a = A // ok, a: E1 enum E2 { | B(Bool) } let b = B // error // 不能作为一等公民 enum E3 { | C | C(Bool) } let c = C // ok, c: E3作为一种自定义类型,
enum类型默认不支持使用==(!=)进行判等(判不等)当然, 可以通过重载
==(!=)操作符使得自定义的enum类型支持==(!=)同一个
enum中支持constructor的重载, 但是只有参数个数参与重载, 参数类型不参与重载, 也就是说, 允许同一个enum中定义多个同名constructor, 但是要求它们的参数个数不同(没有参数的constructor虽不为函数类型, 也可以与其它constructor重载), 例如:enum TimeUnit4 { | Year | Year(Int32) // ok | Year(Float32) // error: redeclaration of 'Year' | Month(Int32, Float32) // ok | Month(Int32, Int32) // error: redeclaration of 'Month' | Month(Int32) // ok | Day(Int32, Float32, Float32) // ok | Day(Float32, Float32, Float32) // error: redeclaration of 'Day' | Day(Float32, Float32) // ok | Hour(Int32, Float32, Float32, Float32) // ok | Hour(Int32, Int32, Int32, Int32) // error: redeclaration of 'Hour' | Hour(Int32, Int32, Int32) // ok }
enum类型支持递归和互递归定义, 例如:// 递归 enum TimeUnit5 { | Year(Int32) | Month(Int32, Float32) | Day(Int32, Float32, Float32) | Hour(Int32, Float32, Float32, Float32) | Twounit(TimeUnit5, TimeUnit5) } // 互递归定义 enum E1 { A | B(E2) } enum E2 { C(E1) | D(E1) }
enum不可以被继承
enum可以实现接口
enum值的访问
enum值有两种访问方式:
第一种是通过
enum名加上constructor名的访问方式第二种是省略
enum名的方式
假设存在:
enum TimeUnit1 {
Year | Month | Day | Hour
}
enum TimeUnit2 {
| Year(Float32)
| Month(Float32, Float32)
| Day(Float32, Float32, Float32)
| Hour(Float32, Float32, Float32, Float32)
}
enum TimeUnit3<T1, T2> {
| Year(T1)
| Month(T1, T2)
| Day(T1, T2, T2)
| Hour(T1, T2, T2, T2)
}第一种方式就是: 通过enum名.constructor(参数)的方式访问
let time1 = TimeUnit1.Year
let time2 = TimeUnit2.Month(1.0, 2.0)
let time3 = TimeUnit3<Int64, Float64>.Day(1, 2.0, 3.0)第二种方式, 则是省略enum名:
let time1 = Year
let time2 = Month(1.0, 2.0)
let time3 = Day<Int64, Float64>(1, 2.0, 3.0)关于第二种使用方式需要满足以下规则:
当不存在其它变量名、函数名、类型名、包名冲突的时候, 可以省略类型前缀使用
否则会优先选择变量名、函数名、类型名或包名
enum类型的解构
使用
match表达式和enum pattern可以实现对 enum 的解构let time12 = TimeUnit1.Year let howManyHours = match (time12) { case Year => 365 * 24 // matched case Month => 30 * 24 case Day => 24 case Hour => 1 } let time13 = TimeUnit2.Month(1.0, 1.5) let howManyHours = match (time13) { case Year(y) => y * 365.0 * 24.0 case Month(y, m) => y * 365.0 * 24.0 + m * 30.0 * 24.0 // matched case Day(y, m, d) => y * 365.0 * 24.0 + m * 30.0 * 24.0 + d * 24.0 case Hour(y, m, d, h) => y * 365.0 * 24.0 + m * 30.0 * 24.0 + d * 24.0 + h }
match表达式的具体使用, 在本篇文档中没有提及, 之后进行阅读
不过大概意思是, match可以匹配enum类型值, 同时可以将值携带的参数数据提取出来使用
enum的其他成员
enum中也可以定义成员函数、操作符函数和成员属性
- 定义普通成员函数 参见[函数定义]
- 定义操作符函数的语法 参见[操作符重载]
- 定义成员属性的语法 参见[属性的定义]
enum中的constructor、静态成员函数、实例成员函数之间不能重载因此,
enum的constructor、静态成员函数、实例成员函数、成员属性之间均不能重名
虽然本篇文档中没有涉及成员函数、操作符函数和成员属性的定义语法
但是有一个简单的例子:
enum Foo {
A | B | C
func f1() {
f2(this)
}
static func f2(v: Foo) {
match (v) {
case A => 0
case B => 1
case C => 2
}
}
prop item: Int64 {
get() {
f1()
}
}
}
main() {
let a = Foo.A
a.f1()
Foo.f2(a)
a.item
}大致可以看出, 成员函数可以通过enum值调用, 静态成员函数还可以通过enum类型直接调用
成员属性, 可以通过值访问, 调用get()方法, 应该还有set()方法
Option类型
Option type是一种泛型enum类型:enum Option<T> { Some(T) | None }
Some和None是两个constructor,Some(T)表示一种有值的状态,None表示一种无值的状态类型变元
T被实例化为不同的类型, 会得到不同的Option type, 例如:Option<Int32>、Option<String>等
Option是仓颉标准提供的一个泛型enum类型
“Some和None是两个constructor, Some(T)表示一种有值的状态, None表示一种无值的状态”
也就是说, Option可以包装数据类型, 如果是Some(数据)就表示有值, 如果是None就表示无值
可以举个简单的例子理解:
假设有一个函数, 如果执行正确, 会返回一个字符串, 但是 如果执行错误就不返回字符串, 此时返回值的类型就可以设置为Option<String>:
func getStr(n: Int32): Option<String> {
if (n < 10) {
return "a String"
}
return None
}
main() {
let result1 = getStr(5)
let result2 = getStr(10)
match (result1) {
case Some(str) => println(str)
case None => println("get None")
}
match (result2) {
case Some(str) => println(str)
case None => println("get None")
}
return 0
}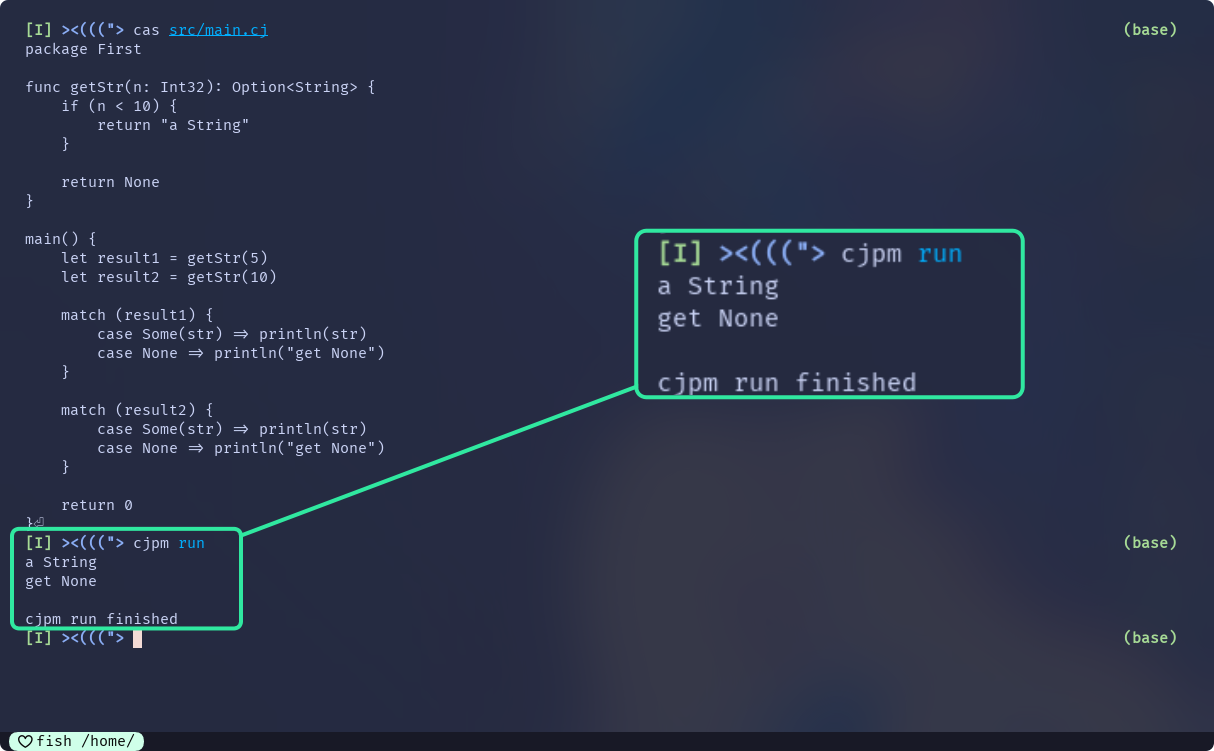
Option可以通过match进行匹配, 实现特定的处理
且, Option的match, None是必须处理的, 这可以看作一种强制判空的处理
Option的用法, 类似返回C/C++中的返回指针, 可能返回的是nullptr也可能是有效的指针, 所以获取返回值之后一般需要手动判空, 如果忘记判空, 可能会出现一定的问题
而仓颉中, 如果要使用返回值, 就需要强制处理有值和空的情况, 更安全
ption类型的另一种写法是在类型名前加?, 即对于任意类型Type,?Type等价于Option<Type>例如,
?Int32等价于Option<Int32>,?String等价于Option<String>等等关于
Option类型, 需要注意:
虽然
T和Option<T>是不同的类型, 但是当明确知道某个位置需要的是Option<T>类型的值时, 可以直接传一个T类型的值, 编译器会将T类型的值封装成Option<T>类型的Some constructor例如, 下面的定义是合法的
let v1: ?Int64 = 100 let v2: ??Int64 = 100对于两个不相等的类型
T1和T2, 即使它们之间拥有子类型关系,Option<T1>和Option<T2>之间也不会构成子类型关系
Option类型的使用遵循泛型enum类型的使用规则例如, 可以定义一系列不同
Option类型的变量:let opInt32_1 = Some(100) // The type of 'opInt32_1' is 'Option<Int32>' let opInt32_2 = Option<Int32>.None // The type of 'opInt32_2' is 'Option<Int32>' let opChar = Some('m') // The type of 'opChar' is 'Option<Rune>' let opBool = Option<Bool>.None // The type of 'opBool' is 'Option<Bool>' enum TimeUnit1 { Year | Month | Day | Hour } let opEnum = Some(TimeUnit1.Year) // The type of 'opEnum' is 'Option<TimeUnit1>'
Option值的解构
提供若干方式以方便对 Option 值的解构: 模式匹配、
getOrThrow函数、coalescing操作符(??)和问号操作符(?)
Option类型是一种enum类型, 因此可以使用模式匹配表达式中的enum pattern实现Option值的解构let number1 = match (opInt32_1) { case Some(num) => num case None => 0 } let number2 = match (opInt32_2) { case Some(num) => num case None => 0 } let enumValue = match (opEnum) { case Some(tu) => match (tu) { case Year => "Year" // matched case Month => "Month" case Day => "Day" case Hour => "Hour" } case None => "None" }对于
Option<T>类型的表达式e, 通过调用函数getOrThrow()或getOrThrow(exception: ()->Exception)实现对e的解构:如果
e的值等于Option<T>.Some(v), 则e.getOrThrow()(或e.getOrThrow(lambdaArg))的值等于v的值;如果
e的值等于Option<T>.None, 则e.getOrThrow()在运行时抛出NoneValueException异常(e.getOrThrow(lambdaArg)在运行时抛出lambdaArg中指定的异常)let number1 = opInt32_1.getOrThrow() // number1 = 100 let number2 = opInt32_2.getOrThrow() // throw NoneValueException let number3 = opInt32_2.getOrThrow{ MyException("Get None value") } // throw MyException对于
Option<T>类型的表达式e1和T类型的表达式e2, 表达式e1 ?? e2的类型为T当
e1的值等于Option<T>.Some(v)时,e1 ?? e2的值等于v的值;当
e1的值等于Option<T>.None时,e1 ?? e2的值等于e2的值let number1 = opInt32_1 ?? 0 // number1 = 100 let number2 = opInt32_2 ?? 0 // number2 = 0问号操作符(
?)是一元后缀操作符
?需和后缀操作符.,(),{}或[]一起使用, 以实现Option<T>对这些后缀操作符的支持对于一个
Option类型的表达式e,e?.b表示当e为 Some 时得到Option<T>.Some(b), 否则得到Option<T>.None(T 为 b 的类型), 其它操作符同理class C { var item = 100 } let c = C() let c1 = Some(c) let c2 = Option<C>.None let r1 = c1?.item // r1 = Option<Int64>.Some(100) let r2 = c2?.item // r2 = Option<Int64>.None
Option在match中的解构, 就是匹配有值和无值两种情况, 并进行处理
同时Option类型的表达式内置函数getOrThrow(), 如果有值则获取值, 如果无值, 则抛出异常
而, Option<T>类型的表达式, 还可以通过e1 ?? e2表达式, 如果有值则获取值, 如果无值 则获取e2这个默认值, e2的类型为T
然后就是?操作符, Option<T>类型表达式后可用?操作符再后接访问T类型内元素的操作符:.、[]、()等, 获取Some(T)或None