
阅读文档版本:
具体开发指南 Cangjie-LTS-1.0.3↗
在阅读 了解仓颉的语言规约时, 难免会涉及到一些仓颉的示例代码, 但 我们对仓颉并不熟悉, 所以可以用仓颉在线体验↗快速验证
有条件当然可以直接配置Canjie-SDK↗
博主在此之前, 基本就只接触过C/C++语言, 对大多现代语言都没有了解, 所以在阅读过程中遇到相似的概念, 难免会与C/C++中的相似概念作类比, 见谅
此样式内容, 表示文档原文内容
表达式
表达式通常由一个或多个操作数(
operand)构成, 多个操作数之间由操作符(operator)连接, 每个表达式都有一个类型, 计算表达式值的过程称为对表达式的求值(evaluation)在仓颉编程语言中, 表达式几乎无处不在, 有表示各种计算的表达式(如算术表达式、逻辑表达式等), 也有表示分支和循环的表达式(如
if表达式、循环表达式等)对于包含多个操作符的表达式, 必须明确每个操作符的优先级、结合性以及操作数的求值顺序
优先级和结合性规定了操作数与操作符的结合方式, 操作数的求值顺序规定了二元和三元操作符的操作数求值顺序, 它们都会对表达式的值产生影响
注: 本章中对于各操作符的操作数类型的规定, 均建立在操作符没有被重载的前提下
循环表达式
仓颉编程语言支持三种循环表达式:
for-in表达式、while表达式和do-while表达式循环表达式的语法定义为:
loopExpression : forInExpression | whileExpression | doWhileExpression ;
for-in表达式
一个完整的
for-in表达式 具有如下形式:for (p in e where c) { s }其中
pattern guard``where c是非必须的, 因此更简易的for-in表达式 具有如下形式:for (p in e) { s }
for-in表达式 的语法定义为:forInExpression : 'for' '(' patternsMaybeIrrefutable 'in' expression patternGuard? ')' block ; patternsMaybeIrrefutable : wildcardPattern | varBindingPattern | tuplePattern | enumPattern ; patternGuard : 'where' expression ;上述语法定义中, 关键字
for之后只能是那些一定或可能为 irrefutable 的 pattern(见 模式的分类↗)在语义检查阶段, 会检查
for之后的 pattern 是否真的是 irrefutable, 如果不是 irrefutable pattern, 则编译报错另外, 如果
for之后的 pattern 中存在 binding pattern, 相当于新声明了一个(或多个)let变量, 每个变量的作用域从它第一次出现的位置到循环体结束
for(pattern in expression patternGuard)
中要求 pattern 必须 一定或可能 irrefutable, 也就是不能总是 refutable
这意味着, for-in表达式, 允许像模式匹配那样, 匹配遍历expression中的元素
但, 必须要能够匹配expression中的所有元素?
就像这样?
for ((i, j) in [(1, 2), (3, 4)]) {
println("Sum = ${i + j}")
}从语法定义来看, 还可以通配符模式、绑定模式、枚举模式进行匹配
但都要满足 irrefutable
且, 如果存在 绑定模式, 相当于声明了新的变量, 也就可能触发遮盖:
let x = 20;
for (x in [1, 2, 3, 4, 5, 6, 7]) {
println(x)
}
// for 中的 x 是绑定模式, 相当于新声明一个变量, 触发遮盖
for-in会先对expression求值, 再调用其iterator()函数, 获取一个类型为Iterator<T>的值程序通过调用
Iterator<T>的next()函数开始执行循环, 我们可以使用pattern匹配迭代的元素, 如果匹配成功(如果存在patternGuard, 也必须同时满足patternGuard的条件), 则执行循环体block, 然后在开始处重新调用next()继续循环, 当next()返回None时循环终止
Iterable<T>和Iterator<T>可在标准库中查阅main(): Int64 { let intArray: Array<Int32> = [0, 1, 2, 3, 4] for (item in intArray) { print(item) // output: 01234 } let intRange = 0..5 for (number in intRange where number > 2) { print(number) // output: 34 } return 0 }
for (pattern in expression patternGuard)
pattern 匹配的是expreesion的迭代器元素, 循环体执行完, 自动调用迭代器的next()函数, 获取迭代下一个值
while表达式
while表达式的语法定义为:whileExpression : 'while' '(' ('let' deconstructPattern '<-')? expression ')' block ;其中
while是关键字,while之后是一个小括号, 小括号内可以是一个表达式或者一个let声明的解构匹配, 接着是一个块一个基础的
while表达式举例:main(): Int64 { var hundred = 0 while (hundred < 100) { // until hundred = 100 hundred++ } return 0 }
while表达式首先对while之后的表达式进行求值(要求表达式的类型为Bool), 如果表达式的值等于true, 则执行它之后的块, 接着重新计算表达式的值并判断是否重新执行一次循环; 如果表达式的值等于false, 则终止循环
如果while()的括号内是普通Bool类型表达式, 那么就与C/C++中的while表达式一样
如果表达式值为true, 那么就去执行循环体
不过, 仓颉中的while还有一种let解构匹配的模式
对于包含
let的while表达式, 我们称之为while-let表达式我们可以用
while-let表达式来做一些简单的解构操作一个基础的
while-let表达式举例:main(): Int64 { var x: Option<Int64> = Option<Int64>.Some(100) // while-let expression while (let Some(v) <- x) { print("x has value") x = ... } return 0 }
while-let表达式首先对<-之后的表达式进行求值(表达式的类型为可以是任意类型), 如果表达式的值能匹配let之后的 pattern, 则执行它之后的块, 接着重新计算表达式的值然后再次匹配并判断是否重新执行一次循环; 如果匹配失败, 则终止当前的while循环
let之后的 pattern 支持常量模式、通配符模式、绑定模式、Tuple模式、enum模式
while-let与之前的if-let是类似的(见条件表达式↗)
do-while表达式
do-while 表达式的语法定义为:
doWhileExpression : 'do' block 'while' '(' expression ')' ;与
while表达式不同的是:
while表达式在第一次循环迭代时, 如果表达式expression的值为false, 则循环体不会被执行;然而对于
do-while表达式, 第一次循环迭代时, 先执行循环体block, 然后再根据表达式expression的值决定是否再次执行循环体, 也就是说do-while表达式中的循环体会至少执行一次例如:
main(): Int64 { var hundred = 0 do { hundred++ } while (hundred < 100) return 0 }
循环表达式总结
for-in、while和do-while这三种循环表达式的表达能力是等价的通常, 在知道循环的次数或遍历一个序列中的所有元素时使用
for-in表达式;在不知道循环的次数, 但知道循环终止条件时使用
while或do-while表达式三种循环表达式的类型均为
Unit由于
break、continue表达式必须有包围着它们的循环体, 所以对于三种循环表达式, 其循环条件中出现的break或continue均会绑定到其最近的外层循环;如外层不存在循环, 则报错
例如:
while (true) { println("outer") // printed once do { println("inner") // printed once } while (break) // stop the execution of the outer loop println("unreached") // not printed }
try表达式
根据是否涉及资源的自动管理, 将
try表达式分为两类: 不涉及资源自动管理的普通 try 表达式, 以及会进行资源自动管理的try-with-resources表达式
try表达式的语法为:tryExpression : 'try' block 'finally' block | 'try' block ('catch' '(' catchPattern ')' block)+ ('finally' block)? | 'try' '(' resourceSpecifications ')' block ('catch' '(' catchPattern ')' block)* ('finally' block)? ;普通
try表达式 的主要目的是错误处理, 详见[异常]章节
try-with-resources表达式的主要目的是自动释放非内存资源, 详见[异常]章节
没了解过其他现代语言, 只了解C++中的异常
所以对于普通try有一定的了解, 仓颉中的try在异常时具体再看
控制转移表达式
控制转移表达式会改变程序的执行顺序
控制转移表达式的类型是
Nothing类型, 该类型是任何类型的子类型仓颉编程语言提供如下控制转移表达式:
breakcontinuereturnthrow控制转移表达式可以像其他表达式一样, 作为子表达式成为复杂表达式的一部分, 但是有可能会导致产生不可达代码(不可达部分会编译告警):
main(): Int64 { return return 1 // warning: the left return expression is unreachable }
仓颉中明确表示, break``continue``return``throw表达式类型是Nothing
控制转移表达式中:
break和continue必须有包围着它们的循环体, 且该循环体无法穿越函数边界;
return必须有包围着它的函数体, 且该函数体无法穿越;对
throw不作要求“包围着的循环体”无法穿越”函数边界”
在下面的例子中,
break出现在函数f中, 外层的while循环体不被视作包围着它的循环体;
continue出现在lambda表达式 中, 外层的while循环体不被视作包围着它的循环体while (true) { func f() { break // Error: break 必须直接在循环内使用 } let g = { => continue // Error: continue 必须直接在循环内使用 } }控制转义表达式的语法为:
jumpExpression : 'break' | 'continue' | 'return' expression? | 'throw' expression ;
目前看来, 仓颉的break与C/C++不同, 仓颉的break只能直接用在循环体内
break表达式
break表达式只能出现在循环表达式的循环体中, 并将程序的执行权交给被终止循环表达式之后的表达式例如, 下面的代码通过在
while循环体内使用break表达式, 实现在区间[1, 49]内计算4和6的最小公倍数main(): Int64 { var index: Int32 = 0 while (index < 50) { index = index + 1 if ((index % 4 == 0) && (index % 6 == 0)) { print("${index} is divisible by both 4 and 6") // output: 12 break } } return 0 }需要注意的是, 当
break出现在嵌套的循环表达式中时, 只能终止直接包围它的循环表达式, 外层的循环并不会受影响例如, 下面的程序将输出 5 次
12 is divisible by both 4 and 6, 且每次同时会输出i的值:main(): Int64 { var index: Int64 = 0 for (i in 0..5) { index = i while (index < 20) { index = index + 1 if ((index % 4 == 0) && (index % 6 == 0)) { print("${index} is divisible by both 4 and 6") break } } print("${i}th test") } return 0 }
仓颉的break用法基本与C/C++中break在循环体中的用法是一致的
只能跳出所在层的循环, 对更外层循环无用
continue表达式
continue表达式只能出现在循环表达式的循环体中, 用于提前结束离它最近循环表达式的当前迭代, 然后开始新一轮的循环(并不会终止循环表达式)例如, 下面的代码输出区间
[1,49]内所有可以同时被4和6整除的数(12、24、36、48), 对于其他不满足要求的数, 同样会显式地输出main(): Int64 { var index: Int32 = 0 while (index < 50) { index = index + 1 if ((index % 4 == 0) && (index % 6 == 0)) { print("${index} is divisible by both 4 and 6") continue } print("${index} is not what we want") } return 0 }
continue的用法, 也基本与C/C++一致
return表达式
return表达式只能出现在函数体中, 它可以在任意位置终止函数的执行并返回, 实现控制流从被调用函数到调用函数的转移
return表达式有两种形式:return和return expr(expr是一个表达式)
若为
return expr的形式, 我们将expr的值作为函数的返回值, 所以要求expr的类型与函数定义中的返回类型保持一致// return expression func larger(a: Int32, b: Int32): Int32 { if (a >= b) { return a } else { return b } }若为
return的形式, 我们将其视为return ()的语法糖, 所以要求函数的返回类型也为Unit// return expression func equal(a: Int32, b: Int32): Unit { if (a == b) { print("a is equal to b") return } else { print("a is not equal to b") } }需要说明的是,
return表达式作为一个整体, 其类型并不由后面跟随的表达式决定(return后面跟随的表达式为()), 而是Nothing类型
return的用法, 也基本与C/C++保持一致
但, 仓颉中return拥有具体类型:Nothing. 且恒为Nothing
return是return ()的语法糖, 就像C/C++中, 如果函数返回值类型为void, 可以不使用return, 也可以执行return;
throw表达式
throw表达式用于抛出异常, 在调用包含throw表达式的代码块时, 如果throw表达式被执行到, 就会抛出相应的异常, 并由事先定义好的异常处理逻辑进行捕获和处理, 从而改变程序的执行流程下面的例子中, 当除数为 0 时, 抛出算术异常:
func div(a: Int32, b: Int32): Int32 { if (b != 0) { return a / b } else { throw ArithmeticException() } }关于
return和throw表达式, 本节只做了最简单的使用举例, 有关它们的详细介绍, 请分别参见函数和异常章节
如果没有了解过任何编程语言, 要深入理解还是要参阅具体的文档
数值类型转化表达式
数值类型转换表达式用于实现数值类型间的转换, 它的值是类型转换后的值, 它的类型是转换到的目标类型(但原表达式的类型不受目标类型影响), 详细的转换规则可参见 类型转换↗
数值类型转换表达式的语法定义为:
numericTypeConvExpr : numericTypes '(' expression ')' ; numericTypes : 'Int8' | 'Int16' | 'Int32' | 'Int64' | 'UInt8' | 'UInt16' | 'UInt32' | 'UInt64' | 'Float16' | 'Float32' | 'Float64' ;
仓颉的数值类型转换表达式, 其实就是C/C++中的最普通的强制类型转换
只不过, 仓颉只允许数值类型(整型、浮点型)之间进行强制类型转换
this和super表达式
this和super表达式分别使用this和super表示
this可以出现在所有实例成员函数和构造函数中, 表示当前实例
super只能出现在class类型定义中, 表示当前定义的类型的直接父类的实例(详见[类])禁止使用单独的
super表达式
this和super表达式的语法定义为:thisSuperExpression : 'this' | 'super' ;
仓颉的this我能理解等价于C++类中的this指针, 表示当前实例
super我也理解是存在继承关系的类中, 表示直接父类实例
但我不理解什么叫禁止单独使用super表达式?
不就是应该像使用this一样, 直接通过super访问父类的成员吗? 意思是必须通过super访问、调用成员? 不能直接访问super本身?
spawn表达式
spawn 表达式用于创建并启动一个
thread, 详见[并发]章节
看来是仓颉中, 创建线程的方式
synchronized表达式
synchronized 表达式用于同步机制中, 详见[并发]章节
仓颉用于线程同步机制的方式
括号表达式
括号表达式是指使用圆括号括起来的表达式
圆括号括起来的子表达式被视作一个单独的计算单元被优先计算
括号表达式的语法定义为:
parenthesizedExpression : '(' expression ')' ;括号表达式举例:
1 + 2 * 3 - 4 // The result is 3. (1 + 2) * 3 - 4 // The result is 5.
就是数学中可以将表达式作为整体运算的括号
后缀表达式
后缀表达式 由表达式加上后缀操作符构成
根据后缀操作符的不同, 分为: 成员访问表达式、函数调用表达式、索引表达式
在成员访问表达式、函数调用表达式、索引表达式中的后缀操作符的前面, 可以使用可选的
?操作符, 以实现Option类型对这些后缀操作符的支持关于
?操作符, 详见下文介绍后缀表达式的语法定义为:
postfixExpression : atomicExpression | type '.' identifier | postfixExpression '.' identifier typeArguments? | postfixExpression callSuffix | postfixExpression indexAccess | postfixExpression '.' identifier callSuffix? trailingLambdaExpression | identifier callSuffix? trailingLambdaExpression | postfixExpression ('?' questSeperatedItems)+ ;
从文本介绍来看, 后缀表达式应该类似于:obj.mem``func1()``arr[0]等
但, 语法定义中描述了许多内容
还有?操作符, 不过后面有介绍
成员访问表达式
成员访问表达式的语法定义为上述后缀表达式语法的第 3 条:
postfixExpression '.' identifier typeArguments?成员访问表达式可以用于访问
class、interface、struct等的成员
果然, 成员访问表达式 即为 类、接口、结构体访问成员的表达式
成员访问表达式的形式为
T.a
T可以表示为特定的实例或类型名, 我们将其称为成员访问表达式的主体
a表示成员的名字
- 如果
T是类的实例化对象, 通过这种方式可以访问类或接口中的非静态成员- 如果
T是struct的实例, 允许通过实例名访问struct内的非静态成员- 如果
T是类名、接口名或struct名, 允许直接通过类型名访问其静态成员需要注意的是: 类、接口和
struct的静态成员的访问主体只能是类型名
T是this: 在类或接口的作用域内, 可以通过this关键字访问非静态成员T是super: 在类或接口作用域内, 可以通过super关键字访问当前类对象直接父类的非静态成员
C/C++中因为存在值和指针, 所以有两种访问成员的方式.和->
不过, 仓颉中统一通过.访问成员
要注意: 仓颉中静态成员, 只能通过类型名访问, 不能通过具体实例访问
this和super只能在类或接口内部通过.访问非静态成员
对于成员访问表达式
e.a, 如果e是类型名:
- 当
a是e的可变静态成员变量时,e.a是可变的, 其他情况下e.a是不可变的如果
e是表达式(假设e的类型是T):
- 当
T是引用类型时, 如果a是T的可变成员变量, 则e.a是可变的, 否则e.a是不可变的;- 当
T是值类型时, 如果e可变且a是T的可变成员变量, 则e.a是可变的, 否则e.a是不可变的
仓颉通过类型只能访问静态成员, 通过实例只能访问非静态成员
仓颉中的不可变成员, 无论什么时候都不可变
仓颉中的可变成员, 引用类型都可变, 值类型只有实例时可变时, 成员才可变
函数调用表达式
函数调用表达式的语法定义为上述后缀表达式语法的第 4 条, 其中
callSuffix和valueArgument的语法定义为:callSuffix : '(' (valueArgument (',' valueArgument)*)? ')' ; valueArgument : identifier ':' expression | expression | refTransferExpression ; refTransferExpression : 'inout' (expression '.')? identifier ;函数调用表达式用于调用函数, 函数详见第 5 章
对于函数调用表达式
f(x), 假设f的类型是T如果
T是函数类型, 则调用名为f的函数, 否则, 如果T重载了函数调用操作符(), 则f(x)会调用其()操作符重载函数(参见 [可以被重载的操作符])
函数调用的后缀是(), 可加参数可不加参数
加参数可以指定形参进行传参:func1(param1: 1, param2: 2), 不过只适用于函数定义时的命名参数, 且命名参数只能命名传参
非命名参数就只能非命名传参
refTransferExpression意思是引用传参? 应该与C++中的引用传参一样, 可以通过形参直接访问实参(具体还要阅读到函数章节再了解)
索引访问表达式
索引访问表达式的语法定义为上述后缀表达式语法的第 5 条, 其中
indexAccess的语法定义为:indexAccess : '[' (expression | rangeElement) ']' ; rangeElement : '..' | ('..=' | '..' ) expression | expression '..' ;索引访问表达式用于那些支持索引访问的类型(包括
Array类型和Tuple类型)通过下标来访问其具体位置的元素, 详见第 2 章中关于Array类型↗和Tuple类型↗的介绍对于索引访问表达式
e[a](假设e的类型是T):
- 当
T是元组类型时,e[a]是不可变的;- 当
T不是元组类型时, 如果T重载了 set 形式的操作符[](参见 [可以被重载的操作符]), 则e[a]是可变的, 否则e[a]是不可变的对于索引访问表达式
e1[e2], 仓颉语言总是先求值e1至v1, 再将e2求值至v2, 最后根据下标v2选取对应的值或调用相应的重载了的[]操作符
记得在阅读Tuple类型介绍时, 文档中提到使用[]访问元组的元素, []里只能是Int64类型字面量, 应该不能是Range
问号操作符
问号操作符
?为一元后缀操作符, 它必须和上文介绍的后缀操作符.,(),{}或[]一起使用(出现在后缀操作符之前), 实现Option类型对这些后缀操作符的支持, 例如:a?.b,a?(b),a?[b]等等其中
()是函数调用, 当函数调用最后一个实参是lambda时, 可以使用尾闭包语法a?{b}将包含
?.、?()、?{}或?[]的表达式称为 optional chaining 表达式optional chaining 表达式的语法定义为上述后缀表达式语法的最后一条, 其中
questSeperatedItems的语法定义为:questSeperatedItems : questSeperatedItem+ ; questSeperatedItem : itemAfterQuest (callSuffix | callSuffix? trailingLambdaExpression | indexAccess)? ; itemAfterQuest : '.' identifier typeArguments? | callSuffix | indexAccess | trailingLambdaExpression ;关于 optional chaining 表达式, 规定:
对于表达式
e, 将e中的所有?删除, 并且将紧邻?之前的表达式的类型由Option<T>替换为T之后, 得到表达式e1如果
e1的类型是Option类型, 则在e之后使用.、()、{}或[]时, 需要在e和这些操作符之间加上?; 否则, 不应该加?Optional chaining 表达式的类型是
Option<T>(即无论其中有几个?, 类型都只有一层Option), 类型T为 optional chaining 中最后一个表达式(变量或函数名、函数调用表达式、下标访问表达式)的类型一旦 optional chaining 中的某个
Option类型的表达式的值为None, 则整个 optional chaining 表达式的值为None如果 optional chaining 中每个
Option类型的表达式的值都等于某个Some值, 则整个表达式的值为Some(v)(v的类型是最后一个表达式的类型)
解释一下这部分文档内容
?问号操作符实际是作用于Option类型的
即, 如果存在一个变量e的类型是Option<T>类型的, 就可以使用e?.、e?()、e?{}、e?[]来尝试访问成员、调用函数、调用lambda、通过索引访问数据
?之后的操作符, 是根据Option<T>中 这个实际的T决定的, T是类、结构体、interface就用., 是函数就用(), 是lambda就可以用尾闭包{}, 是数组、元组等就可以用[]
?操作符, 通过Option类型, 来安全判断None的情况, 你的Option<T>数据如果是None, 使用?就会取值None, 并终止之后的操作, 整个表达式值就是None. 这对应文档中, 规则3上半部分:
一旦 Optional chaining 中的某个 Option 类型的表达式的值为
None, 则整个 Optional chaining 表达式的值为None
比如:
class Test {
let value = 20
}
func getTest(number: Int64) : Option<Test> {
if (number == 20) {
return Test()
}
return None
}
main(): Int64 {
let res = getTest(20)
println(res?.value)
// println(res.value)
return 0
}如果尝试不用?访问成员, 是会报错的, 因为res是Option类型的, 可能是None, 直接访问成员是不安全的
这段代码的执行结果为:
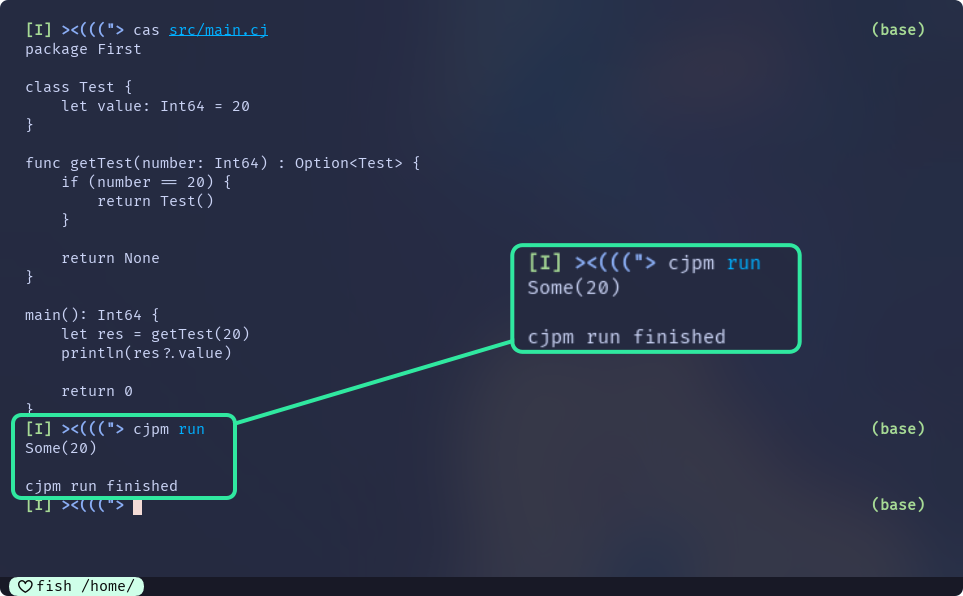
这个结果也对应文档中的规则3的下半部分:
如果 optional chaining 中每个 Option 类型的表达式的值都等于某个
Some值, 则整个表达式的值为Some(v)(v的类型是最后一个表达式的类型)
即, 如果一个完整的 Optional chaining, 链中不存在None, 那么最终结果就是Some(value), value是最终结果的实际类型的数据
其次, 无论Optional chaining有多长, 最终的结果也就只有一层Option, 即a?.b?.c?[2]?()也就只有一层Option, 不是None就是Some(value). 这是规则2的内容
但是对于规则1, 不是很理解. 因为按照规则3, Optional chaining的最终结果一定是Option类型, 如果访问成员或调用函数是一定要加?的, 但规则1说有另外的判断
规则1的意思容易理解为 要根据最终Some(value), value的实际类型来判断是否需要再加?, 但是从实际情况来看无论value是什么类型, 最终Optional chaining的结果是一定要加?的
但是经过不断地测试和验证, 规则1 针对的不是一个完整的Optional chaining
规则1针对的应该是一个Optional chaining的中间过程, 即 如果一个Optional chaining很长, 那么并不是所有的成员访问都需要加?的
可能存在a?.b?.c?.d, 也可能存在a?.b?.c.d, 规则1针对的是类似这种情况, 在Optional chaining的过程中, 如果出现访问到的某个元素是非Option类型的, 那么要用此元素访问其成员或调用函数等操作, 不需要加?, 但最终整个Optional chaining是Option类型的
类似:
class BaseTest {
let value: Int64 = 10
}
class Test {
let value: Int64 = 20
let base = BaseTest()
}
func getTest(number: Int64) : Option<Test> {
if (number == 20) {
return Test()
}
return None
}
main(): Int64 {
let res = getTest(20)
println(res?.base.value)
return 0
}过程中访问到res的成员base, base是非Option类型的, 所以不加?访问其成员
但整个Optional chaining的最终类型就是Option类型
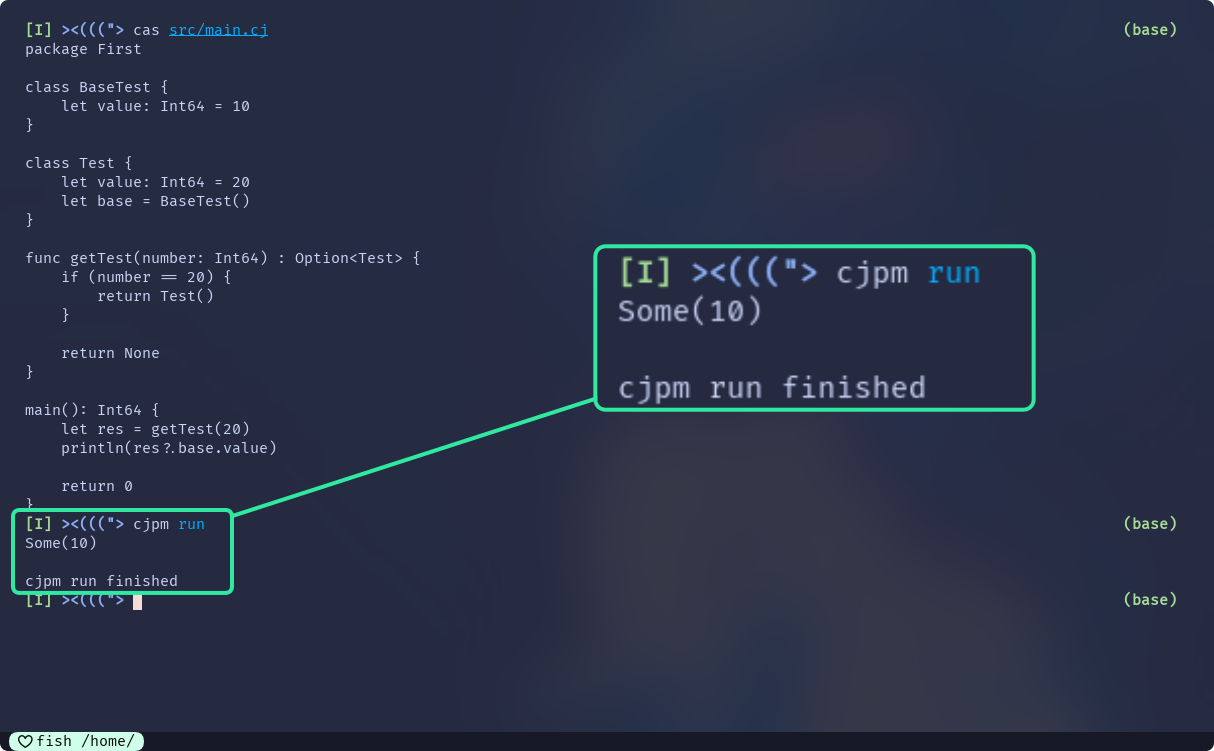
以表达式
a?.b,c?(d)和e?[f]为例, 说明如下:
表达式
a的类型需要是某个Option<T1>且T1包含实例成员b表达式
c的类型需要是某个Option<(T2)->U2>且d的类型为T2表达式
e的类型需要是某个Option<T3>且T3支持下标操作符表达式
a?.b,c?(d)和e?[f]的类型分别为Option<U1>,Option<U2>和Option<U3>, 其中U1是T1中实例成员b的类型,U2是函数类型(T2)->U2的返回值类型,U3是T3执行下标操作的返回类型当
a,c和e的值分别等于Some(v1),Some(v2)和Some(v3)时,a?.b,c?(d)和e?[f]的值分别等于Option<U1>.Some(v1.b),Option<U2>.Some(v2(d))和Option<U3>.Some(v3[f])当
a,c和e的值分别等于None时,a?.b,c?(d)和e?[f]的值分别等于Option<U1>.None,Option<U2>.None和Option<U3>.None(注意这里的b,d和f都不会被求值)事实上, 表达式
a?.b,c?(d)和e?[f]分别等价于如下match表达式:// a?.b 等同于以下匹配表达式 match (a) { case Some(v) => Some(v.b) case None => None<U1> } // c?(d) 等同于以下匹配表达式 match (c) { case Some(v) => Some(v(d)) case None => None<U2> } // e?[f] 等同于以下匹配表达式 match (e) { case Some(v) => Some(v[f]) case None => None<U3> }
即, 对于a?.b、c?(d)或e?[f], 只要a、c、e不是None, 那么最终结果就是Some(a.b)、Some(c(d))或Some(e[f])
结果的最终类型是根据最终Some(value)中value的类型决定的, Option<T>中T即为value的实际类型
再来看一个包含多个
?的多层访问的例子a?.b.c?.d(以?.为例, 其他操作类似, 不再赘述):
表达式
a的类型需要是某个Option<Ta>且Ta包含实例成员b,b的类型中包含实例成员变量c且c的类型是某个Option<Tc>,Tc包含实例成员d表达式
a?.b.c?.d的类型为Option<Td>, 其中Td是Tc的实例成员d的类型;当
a的值等于Some(va)且va.b.c的值等于Some(vc)时,a?.b.c?.d的值等于Option<Td>.Some(vc.d)当
a的值等于Some(va)且va.b.c的值等于None时,a?.b.c?.d的值等于Option<Td>.None(d不会被求值)当
a的值等于None时,a?.b.c?.d的值等于Option<Td>.None(b,c和d都不会被求值)表达式
a?.b.c?.d等价于如下match表达式:// a?.b.c?.d 等同于以下匹配表达式 match (a) { case Some(va) => let x = va.b.c match (x) { case Some(vc) => Some(vc.d) case None => None<Td> } case None => None<Td> }
这个例子中的b的类型就是非Option类型
Optional chaining 也可以作为左值表达式(参见 [赋值表达式]), 例如
a?.b = e1,a?[b] = e2,a?.b.c?.d = e3等赋值表达式的左侧是 Optional chaining 表达式时, 要求 Optional chaining 表达式是可变的(参见 [赋值表达式])
因为函数类型是不可变的, 所以只需要考虑
?.和?[]这两种情况, 并且它们都可以归纳到a?.b = c和a?[b] = c这两种基本的场景(假设a的类型为Option<T>), 规定:
- 对于
a?.b, 仅当T是引用类型且b可变时,a?.b是可变的, 其他情况下a?.b是不可变的- 对于
a?[b], 仅当T是引用类型且重载了 set 形式的操作符[]时,a?[b]是可变的, 其他情况下a?[b]是不可变的当
a?.b(或a?[b])可变时, 如果a的值等于Option<T>.Some(v), 将c的值赋值给v.b(或v[b])如果
a的值等于Option<T>.None, 什么也不做(b和c也不会被求值)类似地, 表达式
a?.b = e1,a?[b] = e2和a?.b.c?.d = e3分别等价于如下match表达式// a?.b = e1 等同于以下匹配表达式 match (a) { case Some(v) => v.b = e1 case None => () } // a?[b] = e2 等同于以下匹配表达式 match (a) { case Some(v) => v[b] = e2 case None => () } // a?.b.c?.d = e3 等同于以下匹配表达式 match (a) { case Some(va) => match (va.b.c) { case Some(vc) => vc.d = e3 case None => () } case None => () }
Option chaining可以当作左值被赋值, 且仅当最后一部分访问符(.或[])前的变量实际是引用类型, 且成员可变或重载set()时, 才能当作左值被赋值
因为从给的例子来看:
// a?.b.c?.d = e3 等同于以下匹配表达式 match (a) { case Some(va) => match (va.b.c) { case Some(vc) => vc.d = e3 case None => () } case None => () }
模式匹配表达式, 中间是直接匹配的va.b.c, 没有其他额外的规则, 只要匹配到了, 即只要最终c是引用类型, 且c.d是可变的就可以进行赋值
下面几个例子, 可以很好的说明, 可以测试一下:
// 全都为引用类型
class C {
var d = 20
}
class B {
let value: Int64 = 10
let c = Some(C())
}
class A {
let b = B()
}
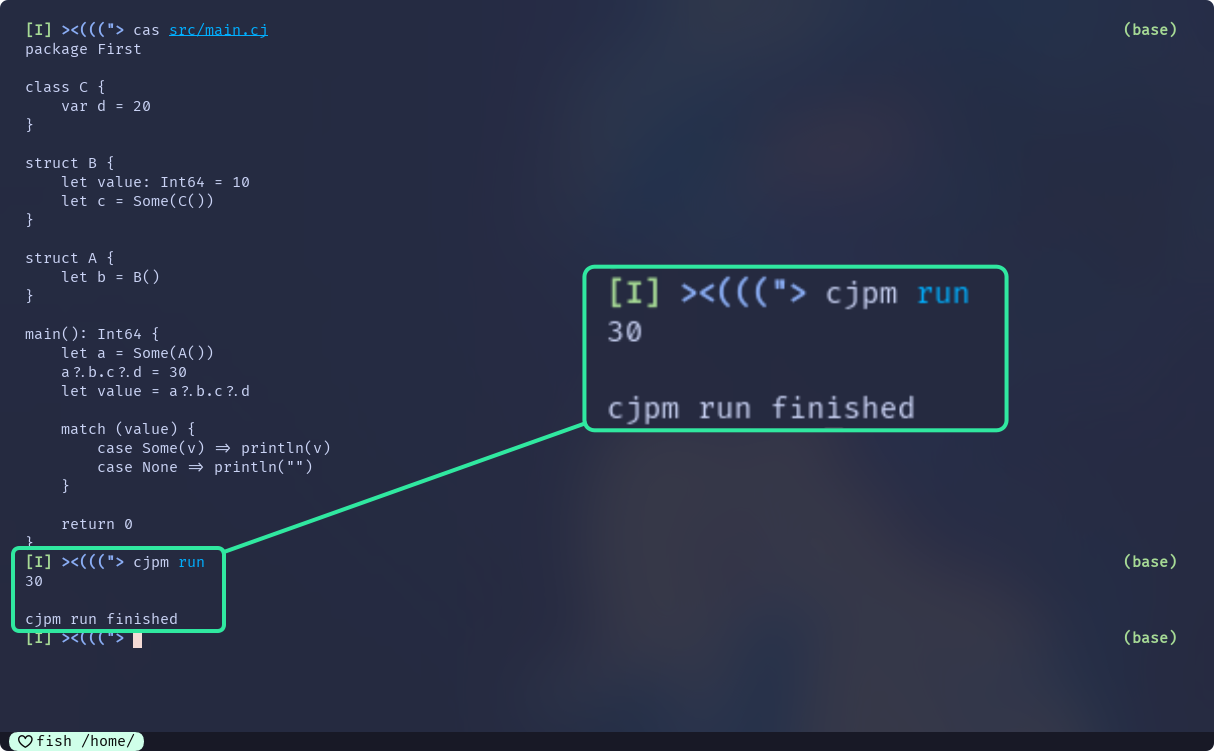
main(): Int64 {
let a = Some(A())
a?.b.c?.d = 30
println(a?.b.c?.d)
return 0
}
// 只有最后一部分为引用类型
class C {
var d = 20
}
struct B {
let value: Int64 = 10
let c = Some(C())
}
struct A {
let b = B()
}
main(): Int64 {
let a = Some(A())
a?.b.c?.d = 30
println(a?.b.c?.d)
return 0
}
// 最后一部分不为引用类型
struct C {
var d = 20
}
class B {
let value: Int64 = 10
let c = Some(C())
}
class A {
let b = B()
}
main(): Int64 {
let a = Some(A())
a?.b.c?.d = 30
println(a?.b.c?.d)
return 0
}最后一个例子是编译不过的, 前两个可以:
操作符
?应用举例:// ?. 用法 class C { var item: Int64 = 100 } let c = C() let c1 = Option<C>.Some(c) let c2 = Option<C>.None let r1 = c1?.item // r1 = Option<Int64>.Some(100) let r2 = c2?.item // r2 = Option<Int64>.None func test1() { c1?.item = 200 // c.item = 200 c2?.item = 300 // no effect } // ?() 用法 let foo = {i: Int64 => i + 1} let f1 = Option<(Int64) -> Int64>.Some(foo) let f2 = Option<(Int64) -> Int64>.None let r3 = f1?(1) // r3 = Option<Int64>.Some(2) let r4 = f2?(1) // r4 = Option<Int64>.None // ?[] 对于元组访问的用法 let tuple = (1, 2, 3) let t1 = Option<(Int64, Int64, Int64)>.Some(tuple) let t2 = Option<(Int64, Int64, Int64)>.None let r7 = t1?[0] // r7 = Option<Int64>.Some(1) let r8 = t2?[0] // r8 = Option<Int64>.None func test3() { t1?[0] = 10 // error: 't1?[0]' is immutable t2?[1] = 20 // error: 't2?[0]' is immutable }