
如果你从未接触过C语言, 那么我建议你先阅读前面的文章:
键盘输入
C语言程序是可以实现, 键盘输入数据到程序中的
C语言标准提供了一些函数, 可以实现从标准输入(一般为键盘)中获取字符、字符串数据, 然后在程序中使用
比如: scanf() gets() fgets() getchar() getc(stdin)
最常用的是scanf(), 本篇文章重点分析scanf()的功能和使用
scanf()**
scanf()的用法, 与printf()几乎一致
#include <stdio.h>
int main() {
int age;
printf("请输入年龄:> ");
scanf("%d", &age);
printf("您输入的年龄为: %d\n", age);
return 0;
}这段代码的功能是, 接收输入的数字, 存储到int age变量中, 再打印出来:
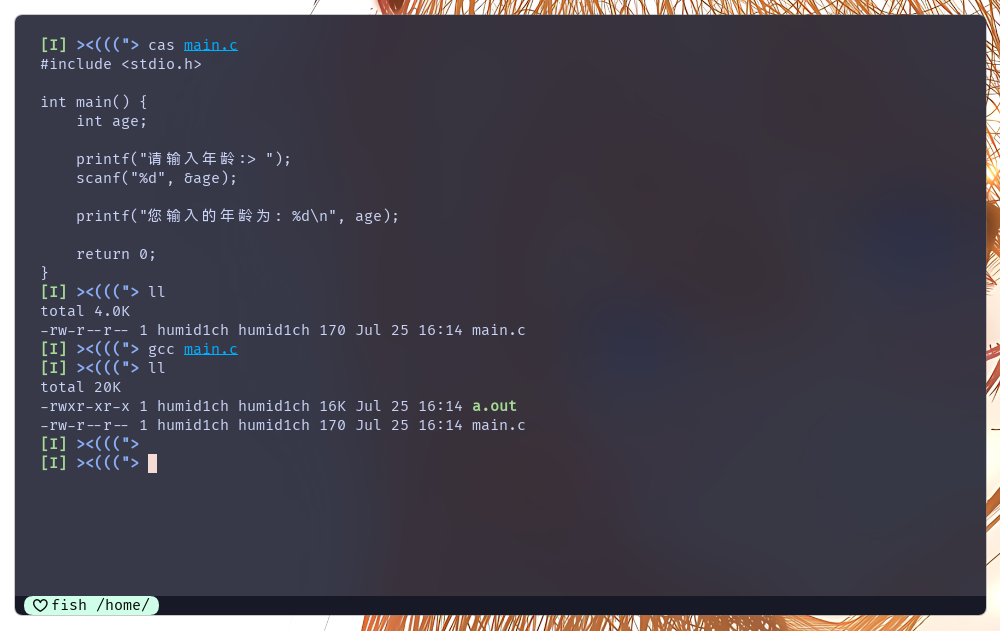
scanf()实现的功能, 目前可以理解为三个大步骤:
- 从键盘接收字符串
- 按照代码中调用
scanf()时的格式字符串, 对接收到的字符串进行格式化解析 - 将解析到的对应格式的数据, 存储到调用
scanf()时传入的变量中
scanf("%d", &age); 的目标作用就是, 接收输入字符串, 并将字符串解析为%d对应的类型, 并将解析出来的数据写入到变量age的内存空间中
& 是取地址符, 可以用来获取变量的内存空间的地址
scanf()需要传入地址, 才能将解析到的格式化数据, 存储到对应的变量的内存空间中, 这个地址就是目标变量的内存空间的地址
C语言中, 想要改变变量的值, 就需要找到此变量的内存空间的地址,然后改变内存空间种的数据, 就是改变这个变量的值
现阶段, 在使用scanf()时, 最好注意一个要求: 输入字符串格式严格与scanf()中传入的格式字符串匹配, 如果你已经对scanf()的实现机制比较熟悉, 可以按照自己的理解随意使用
输入字符串格式严格与scanf()中传入的格式字符串匹配, 是什么意思?
在调用scanf()时, 会先传入格式字符串, 在传入接收数据的变量地址:
scanf("%d, %d, %s", &age, &height, name);如果格式字符串内容是: "%d, %d, %s"
那么在实际输入时, 最好严格按照格式字符串的格式进行输入, 即整型, 整型, 字符串的格式
这样更加安全, 不会偏离预期
以代码为例:
#include <stdio.h>
int main() {
int age = 0;
int height = 0;
char name[32] = {0}; // 初始化能容纳 32 个char类型数据的连续空间
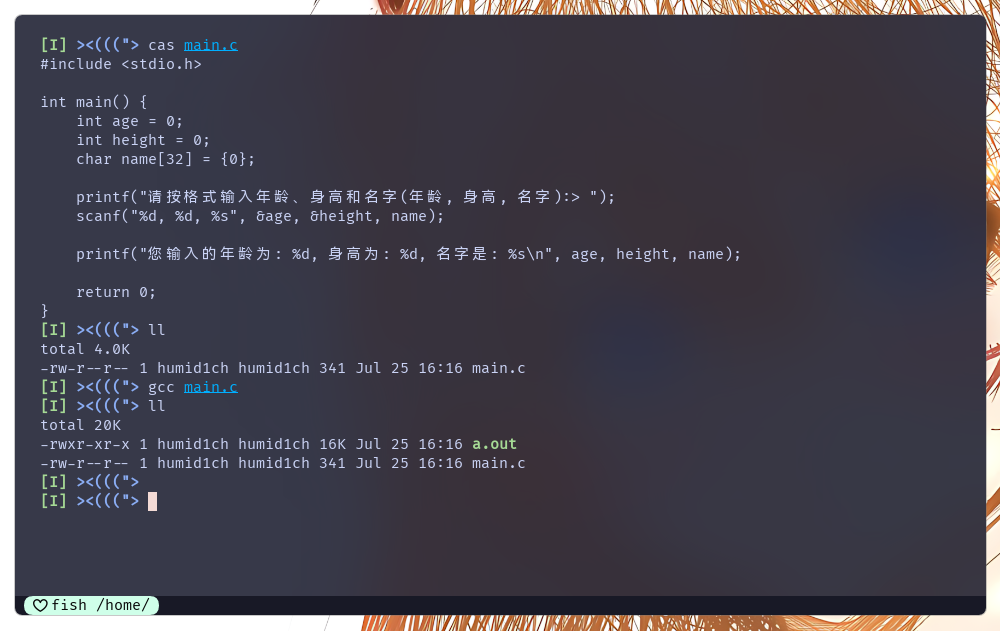
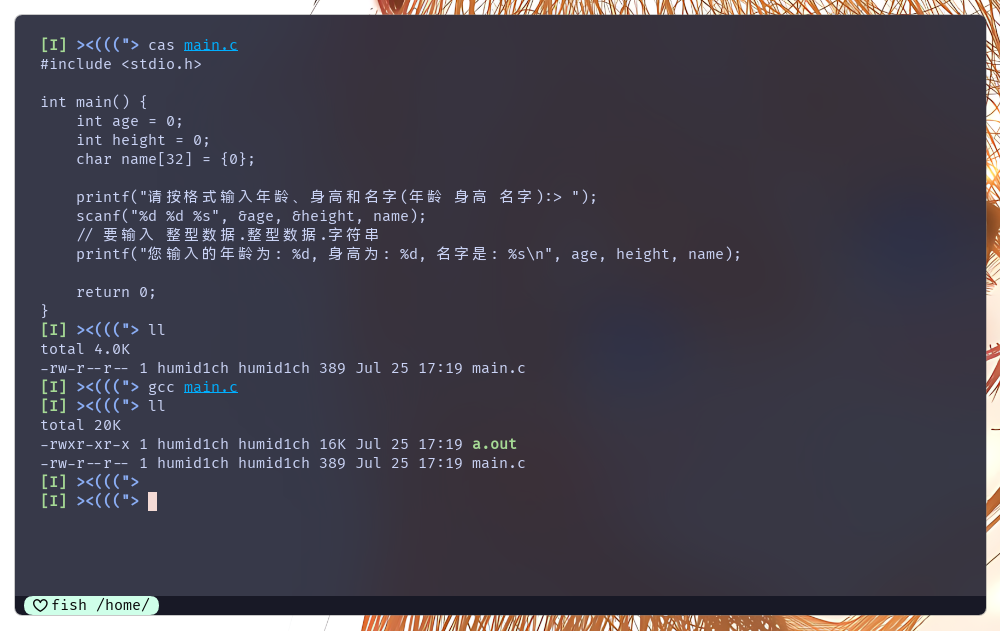
printf("请按格式输入年龄、身高和名字(年龄, 身高, 名字):> ");
scanf("%d, %d, %s", &age, &height, name);
printf("您输入的年龄为: %d, 身高为: %d, 名字是: %s\n", age, height, name);
return 0;
}如果严格按照格式字符串输入, 不会与预期有偏差:
但是如果没有严格按照格式字符串输入, 结果就可能出现偏差:
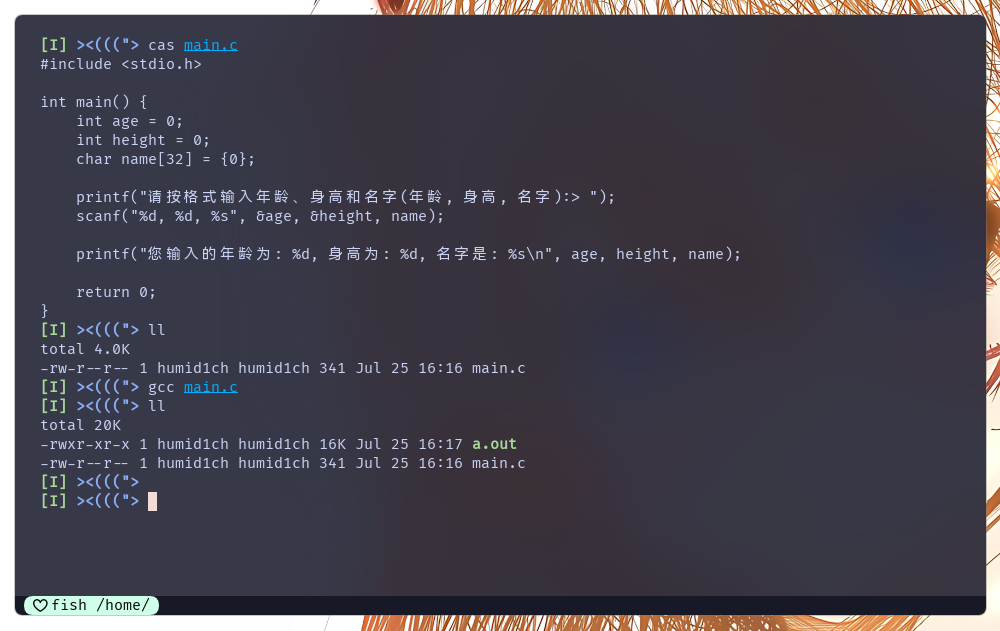
可以发现, 身高和名字并没有输出, 也就意味着 输入的180和humid1ch并没有被接收到
出现这个情况的原因是: scanf()在解析字符时, 如果遇到非目标格式的字符, 会停止接收字符并返回
这里的非目标格式是与调用scanf()时传入的格式字符串做对比的
例子中格式字符串是"%d, %d, %s", 那么在输入时就应该严格按照"整型, 整型, 字符串"的格式输入
scanf()在接收并解析第一个整型数据, 应该接收数字或',', 如果接收到'.', scanf()这个函数会停止接收之后的数据, 并将已经接收并解析好的数据存储到对应的变量中
像"整型.整型.字符串"这样错误的输入, 就会导致只有第一个整型数据被正确接收和解析了
那么, 问题就出现了: 第一个整型数据被正确接收了, 那么后面的字符呢?
要解释这个问题, 就要了解一个概念: C语言程序是存在标准输入缓冲区的
什么是标准输入缓冲区呢?
简单一点理解:
当调用scanf()时, 你可以从键盘输入的内容, 不过 你输入的过程C语言程序是不知道的, 只有在你按下回车之后, 你的终端才会将输入的内容一次性交给C语言程序
并且你输入的内容, 在交给C语言程序之后, 不是直接被scanf()解析, 而是会被C语言程序 在一个空间中存储起来, 然后scanf()会从这个空间中读取数据进行解析
这个存储你键盘输入内容的空间, 就是标准输入缓冲区
了解了这个标准输入缓冲区之后, 你可能已经猜到问题的答案了
第一个整型数据被正确接收了, 那么后面的字符呢?
后面的字符, 依旧留在标准输入缓冲区中, 并且 首个被检测到的不符合格式的字符也会留在标准输入缓冲区中
即, 如果scanf("%d, %d, %s", &age, &height, name);, 但实际输入22.180.humid1ch
scanf()将会只接收解析到22, 并将其存入变量age中, 剩下的.180.humid1ch都会留在标准输入缓冲区中, 之后的代码要从标准输入缓冲区中拿数据时, 拿到标准输入缓冲区中剩余的内容
这个结论是可以通过代码验证的:
#include <stdio.h>
int main() {
int age = 0;
int height = 0;
char name[32] = {0};
printf("请按格式输入年龄、身高和名字(年龄, 身高, 名字):> ");
scanf("%d, %d, %s", &age, &height, name);
// 要输入 整型数据.整型数据.字符串
printf("第一个scanf解析完之后, 您输入的年龄为: %d, 身高为: %d, 名字是: %s\n", age, height, name);
scanf(".%d.%s", &height, name);
printf("第二个scanf解析完之后, 您输入的年龄为: %d, 身高为: %d, 名字是: %s\n", age, height, name);
return 0;
}运行这段代码, 如果输入22.180.humid1ch
第一个scanf()的执行结果我们已经知道了
那么第二个scanf()的执行结果:
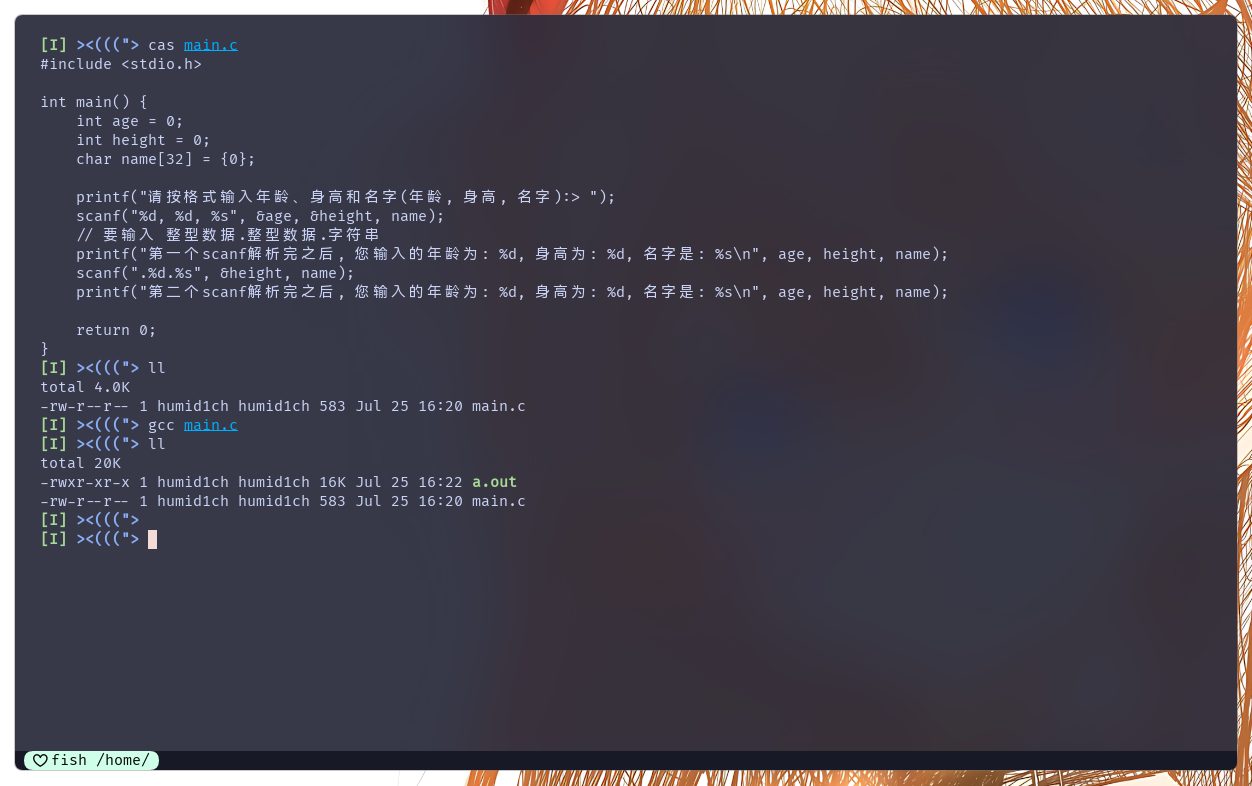
从结果中看, 第二次调用的scanf(".%d.%s", &height, name)直接完整的接收并解析了剩余的".180.humid1ch"
这个现象符合上面的结论
并且, 从现象中可以分析出另一个事实: 当标准输入缓冲区中存在数据时, 再调用scanf(), 不会再要求进行键盘输入
这样的结果也意味着, 事实上scanf()并不是直接对完整的字符串进行解析的, 而是一边接收单个字符, 一边解析
对空白字符的处理
使用scanf()进行键盘输入时, 如果没有 严格按照格式字符串的格式 进行输入, 可能会出现与预期不符的解析情况
但, scanf()的输入也可以不用非常严格, 前提是要使用空白字符
因为 scanf()对空白字符的处理是特殊的, 连续的 空格 \t \n 等不显示的字符, 会被scanf()读取并丢弃
即, 连续的空白字符会被视为单个分隔符, 并且会被自动忽略
这句话有些抽象, 但是通过代码以及运行现象可以很简单的理解:
#include <stdio.h>
int main() {
int age = 0;
int height = 0;
char name[32] = {0};
printf("请按格式输入年龄、身高和名字(年龄 身高 名字):> ");
scanf("%d %d %s", &age, &height, name);
// 要输入 整型数据.整型数据.字符串
printf("您输入的年龄为: %d, 身高为: %d, 名字是: %s\n", age, height, name);
return 0;
}格式字符串为"%d %d %s", 如果要严格遵循, 就需要输入"整型 整型 字符串"
但是scanf()对空白字符串的处理是特殊的, 输入时对数据之间的空格数量是没有限制的:
使用scanf()时, 如果格式字符串中除了格式字符, 不存在其他非空白字符作为分割
那么在输入时, 数据之间可以使用任意数量的空白字符分割
实际上, scanf()的格式字符串中的 空格 \t \n 等空白字符, 表示 跳过任意数量的空白字符
这里的跳过, 是指将空白字符从标准输入缓冲区中取出, 直到遇到非空字符, 会消耗掉缓冲区中的空白字符
在终端输入数据时, 最终的按下的回车, 会作为'\n'被写入到标准输入缓冲区中
如果scanf()中的格式字符串结尾没有'空白字符', 那么在scanf()执行完毕之后, 标准输入缓冲区中依旧会存在一个'\n'
#include <stdio.h>
int main() {
int age = 0;
printf("输入年龄:> ");
scanf("%d", &age);
char theLastChar = getchar();
printf("您输入的年龄为: %d, 最后一个字符的ASCII码值为: %d\n", age, theLastChar);
return 0;
}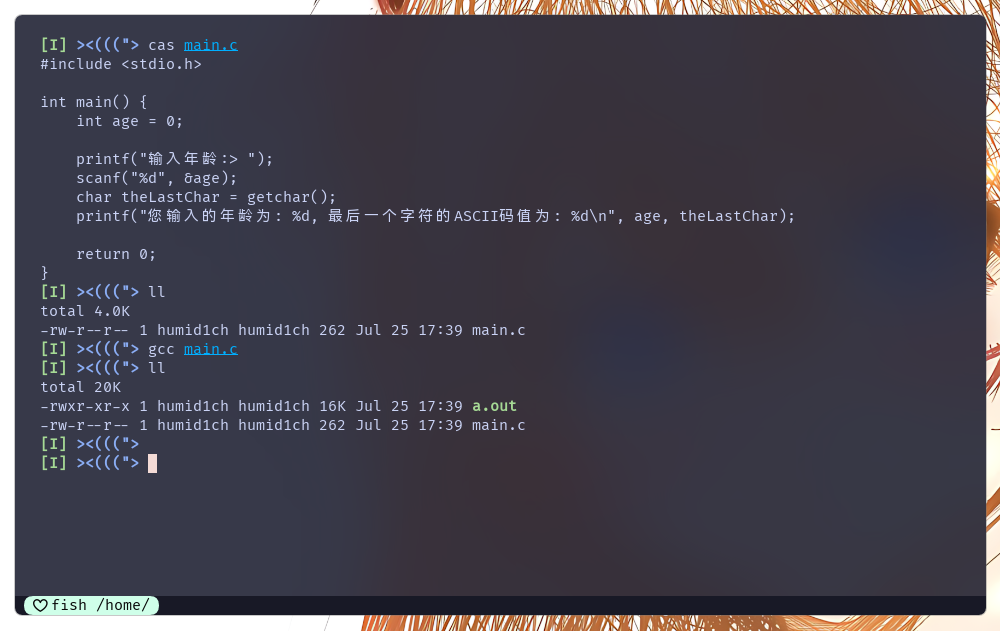
如果标准输入缓冲区不为空, getchar()可以从标准输入缓冲区中取出一个字符
ASCII码表中, '\n'对应的十进制数值就是10
gets() 和 fgets()
gets()和fgets()在C语言中被用来, 从标准输入中读取一行字符串, 直到遇到换行符\n或文件结束EOF, 或输入内容超出目标长度
首先是
gets()使用很简单:
#include <stdio.h> int main() { char inputs[256] = {0}; // 开辟一个能容纳 256 个char类型数据的连续空间, 即 存储输入数据的缓冲区 printf("请输入字符串:> "); gets(inputs); printf("你输入的内容是: %s", inputs); return 0; }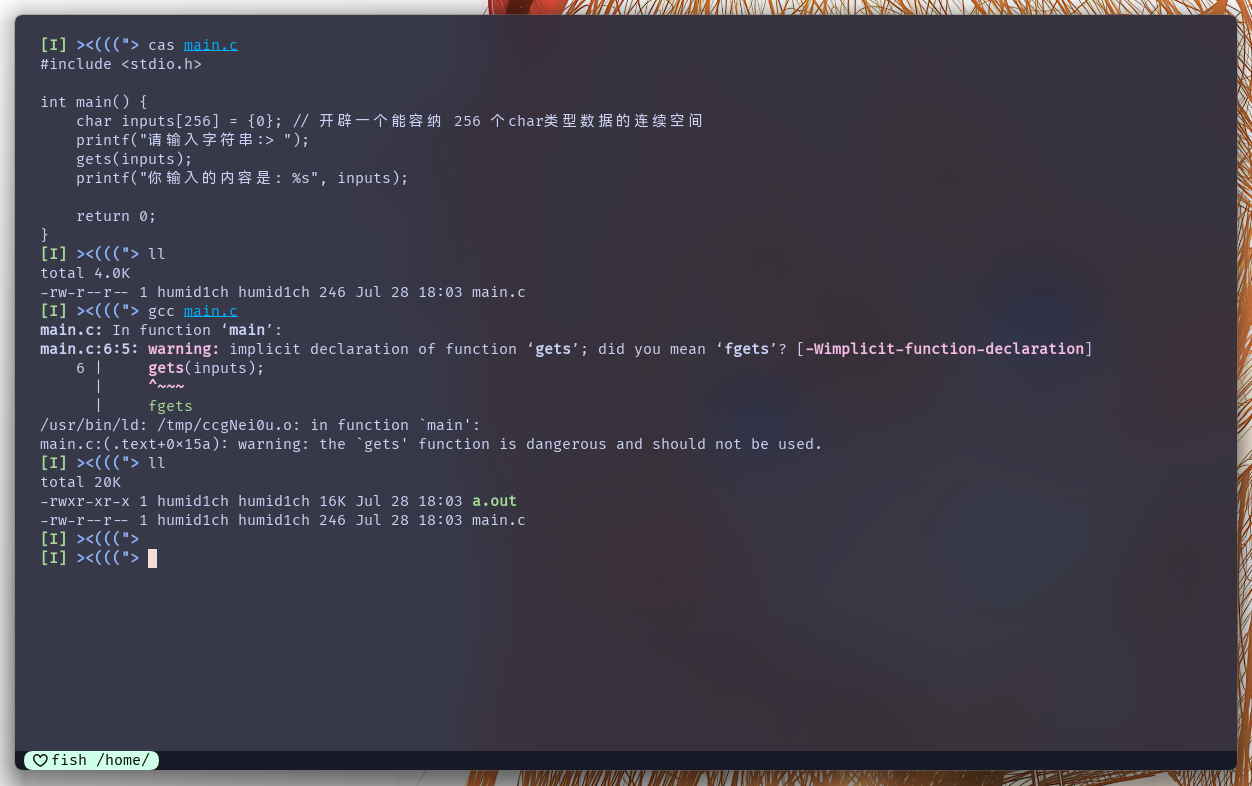
不过,
gets()有一个非常致命的问题: 不能限制输入长度, 也不会判断存储输入数据的缓冲区的大小这会造成一个问题:
以上例来说, 如果
inputs的空间很小, 至少比输入的字符串的长度要小, 在输入结束之后, 可能会造成程序的崩溃假如修改
inputs的大小为2, 即char inputs[2] = {0}: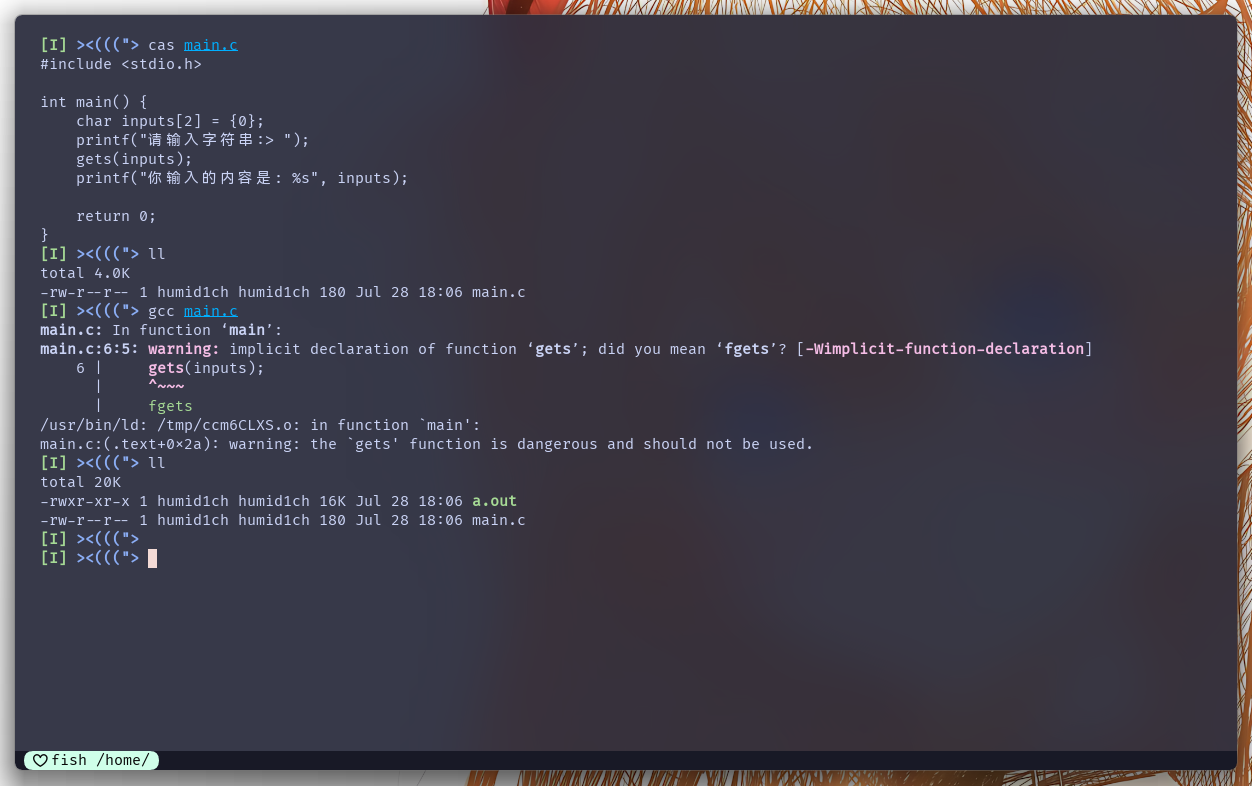
可以看到, 程序并没有打印输入的内容, 而是直接崩溃了:
'./a.out' terminated by signal SIGSEGV (Address boundary error)输入的数据长度超出了, 可容纳的大小, 程序崩溃了
所以
gets()这个函数, 是非常不安全的, 已经被弃用了, 甚至有可能被某些编译器直接删除然后就是
fgets()fgets()的实际作用与gets()是相同的但是,
fgets()是安全的, 在使用时需要指定存储输入数据的缓冲区的大小, 实际存储的内容不会超过输入数据的缓冲区的大小所以, 它可以实现 即使输入数据再长, 也不会超范围存储, 不会造成程序崩溃
使用也很简单:
#include <stdio.h> int main() { char inputs[256] = {0}; printf("请输入字符串:> "); fgets(inputs, sizeof(inputs), stdin); printf("你输入的内容是: %s", inputs); return 0; }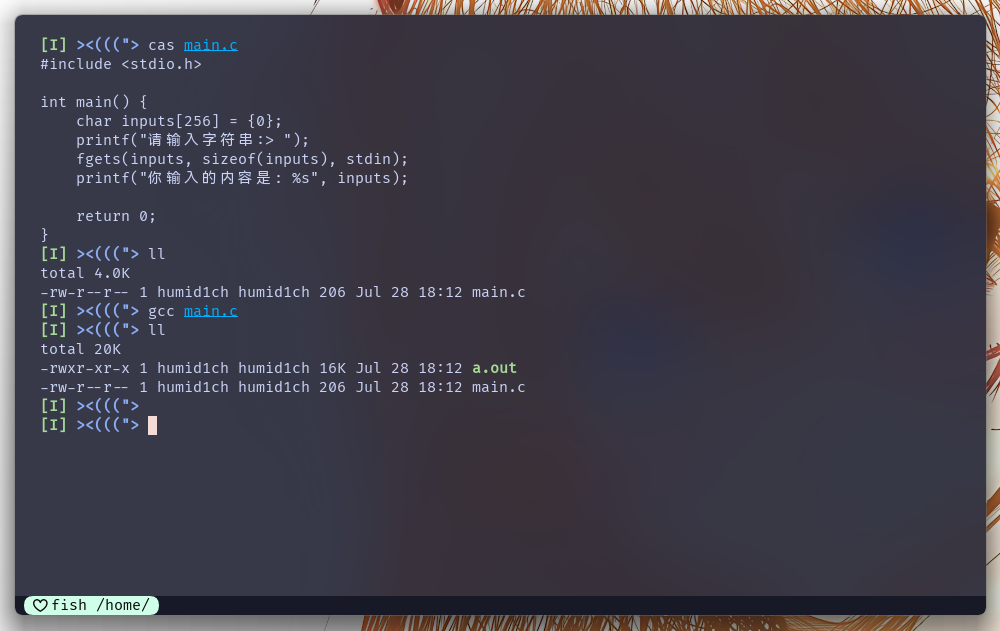
如果
inputs非常小, 但只要fgets()使用正确, 就不会出现输入数据让程序崩溃的情况, 即使输入的数据过分的长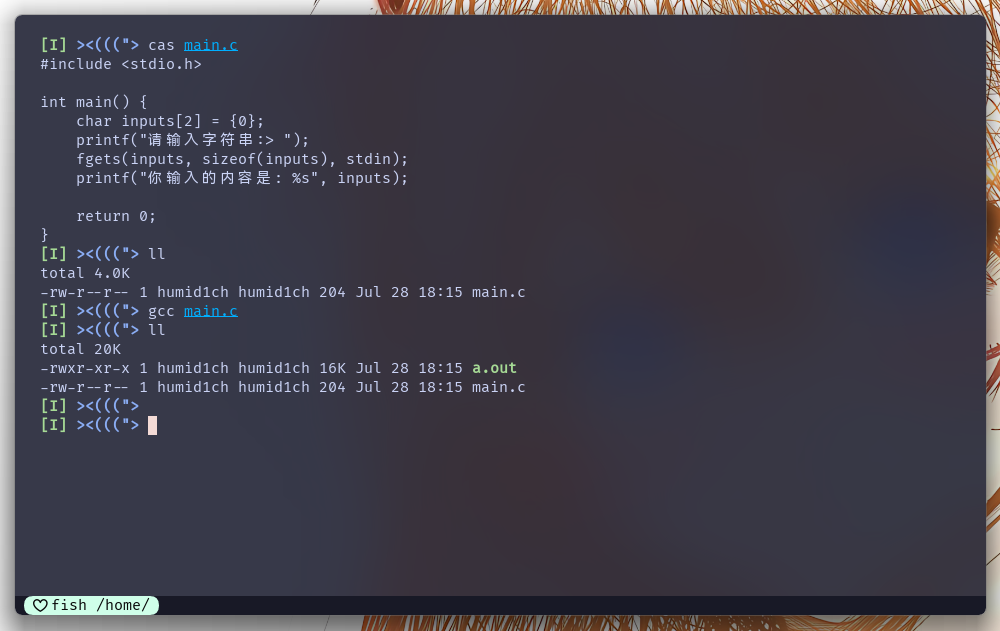
fgets()在使用时必须指定实际接收数据的大小, 这个大小必须<=存储输入数据缓冲区的大小, 否则也可能会造成程序崩溃fgets()在接收数据时, 实际只会接收目标大小-1个字节的数据, 并且会自动在目标缓冲区的最后一个空间填充'\0'作为字符串结尾, 剩余没有接收的输入数据, 依旧保存在输入缓冲区中
getchar() 和 getc(stdin)
getchar()和getc(stdin)的作用只有一个: 从标准输入中读取一个字符, stdin就表示标准输入, 通常默认是键盘输入
事实上, getchar()就是getc(stdin), 所以只介绍其中一个就可以了
这两个函数的使用更简单:
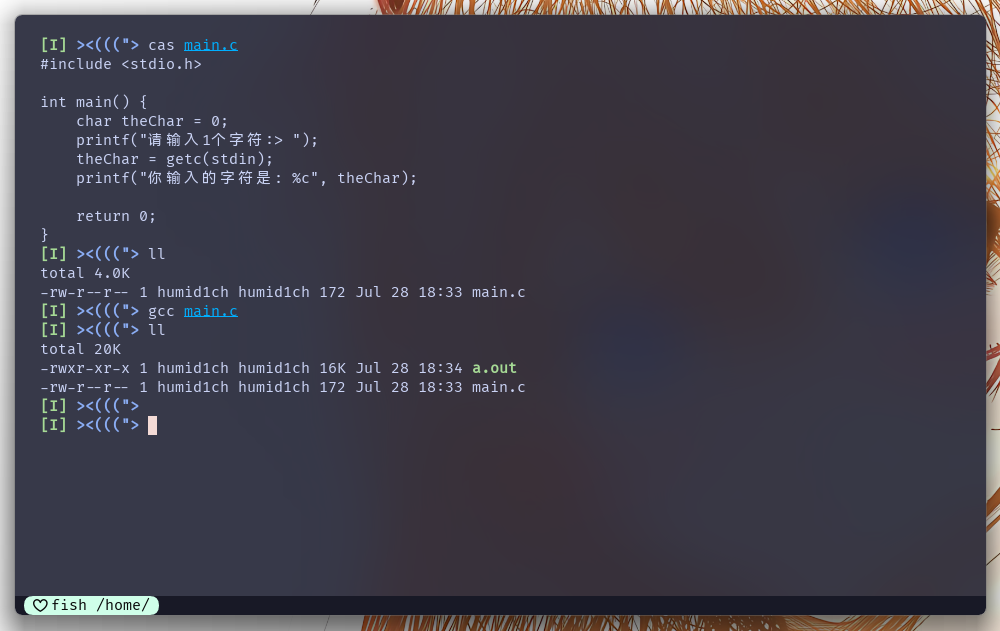
#include <stdio.h>
int main() {
char theChar = 0;
printf("请输入1个字符:> ");
theChar = getc(stdin);
printf("你输入的字符是: %c", theChar);
return 0;
}
与scanf()不同, 在调用scanf()进行输入是, 如果只输入空白字符并回车, scanf()会丢弃所有空白字符, 并判断然你继续输入
但getchar()和getc(stdin)不会判断你输入的是否是空白字符, 他总是会尝试从输入缓冲区中拿出一个字符, 并返回输出
当然, 如果缓冲区为空, 则会阻塞等待输入
getchar()和getc(stdin)也常用来清空标准输入缓冲区:
while (getchar() != EOF)
;