
如果你从未接触过C语言, 那么我建议你先阅读前面的文章:
数组
在C语言中, 你可以定义一个普通的变量来存储一个特定类型的数据, 比如:
int age = 10;定义一个int类型的变量age, 存储一个int类型的数据10, 假设这是存储的一个人的年龄信息
那么现在来思考一个问题: 如果要存储100个人的年龄信息该怎么办?
这样吗:
int age1 = 1;
int age2 = 2;
int age3 = 3;
// ....
int age99 = 99;
int age100 = 100;要定义100次变量吗? 如果你想的话, 当然可以
但是C语言提供了更方便的方式: 数组
什么是数组
C语言可以使用标准提供的基本数据类型定义变量, 来存储特定类型的数据
这个普通的变量, 就好像程序在内存中开辟了一块空间, 给这块空间起了一个名字, 程序就可以使用这块空间了
定义多个变量, 就会在内存中开辟多块空间, 不同变量的空间 在内存中可能是紧挨着的, 也可能是分离开的, 就像这样:

除了普通的变量之外, C语言还提供了数组变量
数组, 允许你一次性在内存中开辟一大块空间, 这快空间内部又可以分为若干块小空间, 每块小空间的大小均为所使用的数据类型的大小, 每个小空间都可以看作为一个普通变量, 可以单独地随意使用
并且与多个普通变量在内存中的分布不同的是, 一个数组变量开辟出来的若干块小空间, 在内存中一定是连续的, 即 一个数组内的空间在内存中都是紧挨着的, 就像这样:

数组中的每一个小空间, 都可以被称为数组的元素
那么, 用官方一点的话来描述数组: 一组相同类型元素的集合
数组的定义与初始化
普通的变量, 我们知道是这样定义的:
int age = 10;那么, 数组变量如何定义呢?
其实在之前的文章中使用过, 也很简单:
int ages[10];
// 或
int ages[10] = { 0 };数组的定义就是在变量名后加上[整数], 整数表示开辟的特定数据类型的小空间的个数, 一般被称为 数组的长度或数组元素的个数
第一个: int ages[10];就表示要开辟10块int类型大小的小空间, 即 这个ages数组的的长度为10, 也就是元素个数为10
另外一个有些不同: 整个int ages[10] = { 0 };完成的不仅仅是开辟一个长度为10的int类型数组, 还有对数组中每个元素初始化为0的操作
即, 定义数组时, 可以使用{ 数据 }的方式, 将数组中所有元素初始化为目标数据, 这是一种数组初始化的方式:
int ages[10] = { 0 }; // 定义一个长度为10的int类型数组, 且每个元素值初始化为0
int chars[10] = { 'A' }; // 定义一个长度为10的char类型数组, 且每个元素值初始化为'A'
...除此之外, 还有另一种定义数组的方式:
int ages[] = { 0, 1, 2, 3, 4 };即, 在变量名后加[](中间没有整数), 即 不需要明确指定数组长度, 但此时必须通过{ 数据1, 数据2, 数据3, ... }进行初始化
这样定义数组, 数组的长度就是{ 数据 }中数据的个数
💡小知识 —— 数组的其他初始化方式
除了上面两种数组初始化的方式, 还存在其他数组初始化的方式:
部分初始化
int ages[10] = { 0, 1, 2, 3, 4 };这种方式不仅在定义时明确指定了数组长度, 而且还在
{}中填写了多个数据, 与上面两种方式都不同, 像是将上面两种方式结合了这种初始化的方式, 实现的效果是:
数组
ages里, 前五个元素按顺序被初始化为{ 0, 1, 2, 3, 4 }, 后五个元素没有指定, 则默认被初始化为0所以, 这种初始化方式可以这样理解:
如果
{}中按顺序填入了n个数据:数组长度 > n:数组的前
n个元素按{}中的数据被初始化, 其余元素均被初始化为0int ages[10] = { 0, 1, 2, 3, 4 };数组长度 == n:数组里的元素就可以看作是
{}int ages[5] = { 0, 1, 2, 3, 4 };数组长度 < n:即
{}中元素个数大于数组长度, 这种初始化方式是C语言中的非法行为:int ages[2] = { 0, 1, 2, 3 };当你尝试编译这样的代码, 编译器会给出警告:
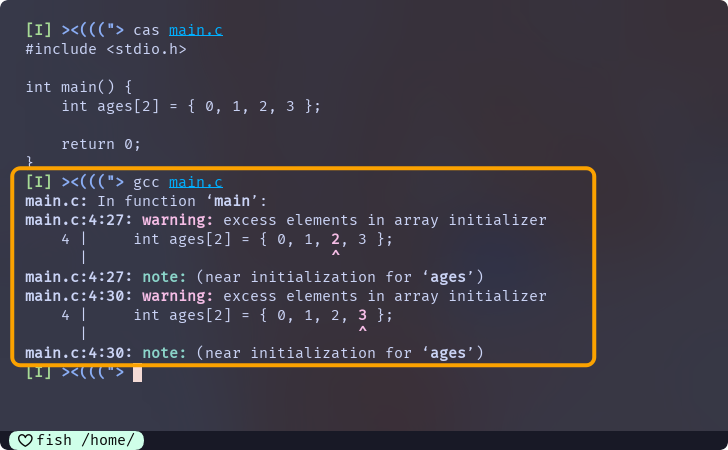
数组初始化列表超出长度, 这是一种违反C语言标准的行为
但是不会发生报错, 编译器会忽略超出长度的部分, 只取数组长度个数的数据进行初始化
指定初始化
int ages[10] = { [0] = 1, [5] = [2], [9] = 3 };这种方式允许对数组
ages中的指定位置的元素进行初始化但这不是C语言最初的标准就支持的, 这是
C99中的标准
数组的使用
数组的定义之后, 肯定是要使用的
那么, 数组该如何使用呢?
我们知道, 数组是开辟了一块大空间, 这块大空间中又可以分为若干块小空间, 小空间的大小均为数据类型的大小
事实上, 数组中的每块小空间是可以看作被标好号的:
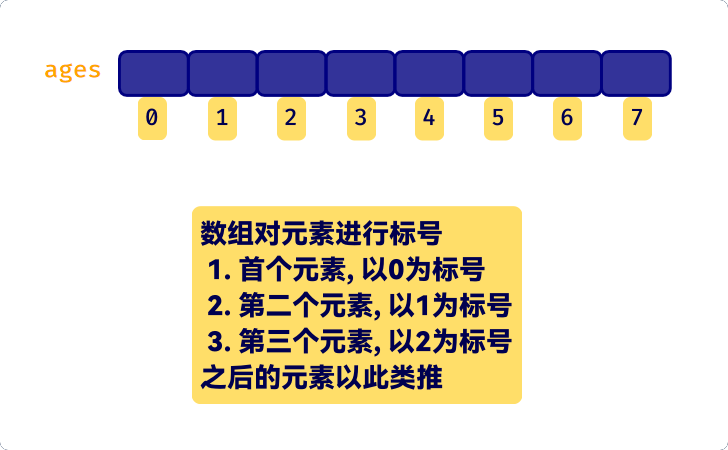
即, 数组中的每一个元素, 都拥有一个下标, 通过下标就可以访问数组的这个元素
但要注意的是: 数组的下标是从0开始的
这句话的意思是:
如果一个数组的长度为10, 那么它下标的范围是[0, 9]
即, 访问它的第1个元素应该使用0作为下标, 相应的如果要访问它的第10个元素应该使用9作为下标
用一个简单的循环来实际演示一下:
#include <stdio.h>
int main() {
int ages[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
for (int i = 0; i < 10; i = i + 1) {
printf("ages[%d]: %d\n", i, ages[i]);
}
return 0;
}先来简单分析一下这段代码:
首先定义了一个数组
ages, 并进行初始化int ages[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };使用
for循环语句, 目的是循环访问数组的不同元素for (int i = 0; i < 10; i = i + 1) { }循环条件是
i < 10,i的初始值为0, 每次循环结束i+1那么总循环次数就是
10次, 对应i的0 ~ 9循环体, 使用
printf()通过i作为数组下标访问数组元素printf("ages[%d]: %d\n", i, ages[i]);ages[i]就是访问数组元素的实际操作
关于数组, 可以直接使用下标来访问目标元素
这段代码的运行结果为:
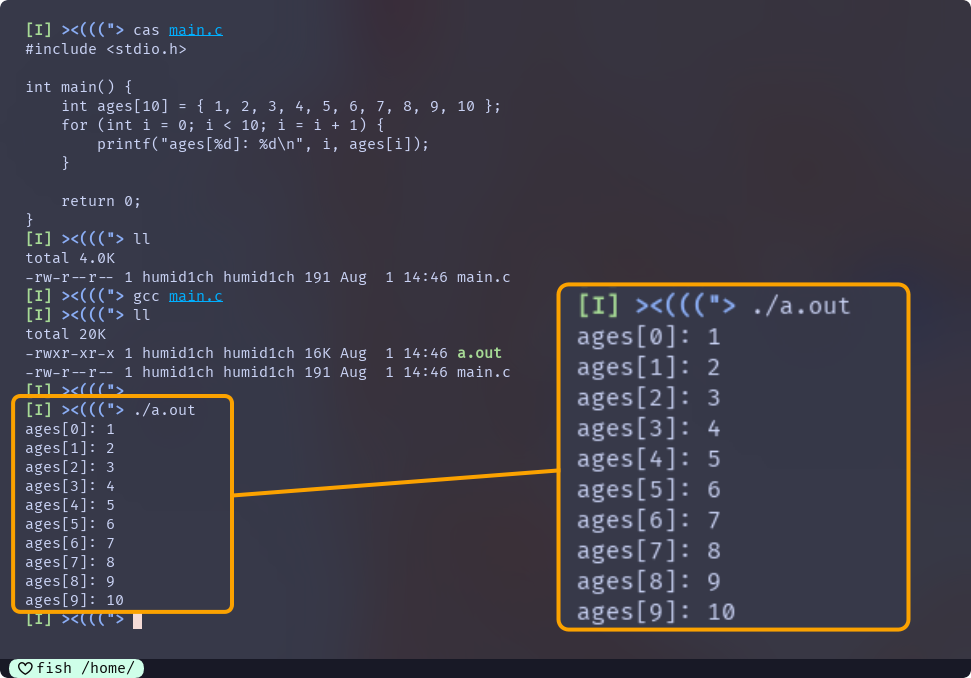
程序的执行没有出现问题
事实上, 要访问定义好的数据的元素, 最简单的方式就是数组名[下标]
但要注意的是, 访问数组元素时使用的下标, 一定不要超出数组范围, 否则就是越界访问, 可能会造成未知的错误
🚨警告 —— 禁止越界访问
什么是越界访问?
在C语言中, 数组的访问方式是数组名[下标], 而下标的合法范围是 [0, 数组长度-1]
int arr[5] = {1, 2, 3, 4, 5};
// 下标的合法范围就是: [0, 4]此时, 如果你要访问数组元素: arr[0] arr[1] arr[2] arr[3] arr[4]都没有问题
但是如果试图这样访问: arr[-1] arr[5]… 就是一种越界访问的情况
简单来说, 一个数组它内部只有n个元素的空间, 要访问它的元素, 下标范围也就只是[0, n-1], 但是如果你试图访问它范围之外的空间, 就可能会造成未知的错误
比如:
#include <stdio.h>
int main() {
int arr[5] = { 1, 2, 3, 4, 5 };
arr[10000] = 20; // 尝试给 arr[10000] 赋值, 已经远远超出数组下标范围
printf("%d\n", arr[10000]); // 尝试访问 arr[10000]
return 0;
}这段代码的运行结果为:
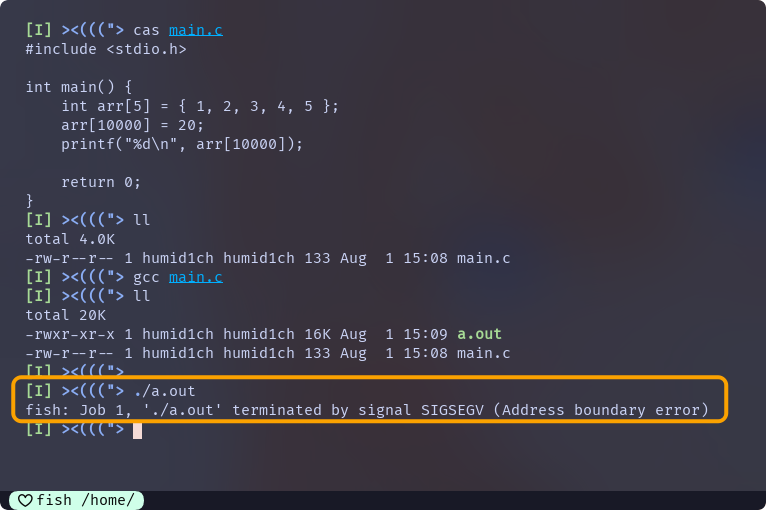
编译没有问题, 即 代码没有语法错误, 但是运行直接崩溃了
事实上, 编译没有问题, 是因为C语言标准并没有对越界访问做出定义, 即 越界访问在C语言中是一种未定义行为
编译器也并不知道这种行为在运行时究竟会发生什么
可能会访问到不该访问的内存空间, 直接崩溃, 就像上面的例子一样
也有可能会访问到其他变量, 因为不同变量所拥有的空间可能并没有相隔太远, 你通过数组 越界可能访问到其他变量的空间
等等等等
出现这些未知后果的具体原因, 在你深入了解过操作系统对程序的管理之后, 应该会有一定的理解
总之要谨记: 越界访问会导致不可预测的后果, 永远确保数组访问在合法范围内!
数组的大小
C语言中, 一个普通变量的大小就是数据类型的大小
那么, 数组的大小呢?
从上面介绍的数组来看, 可以推测数组的大小应该是 数据类型的大小×数组的长度
可以用代码验证一下:
#include <stdio.h>
int main() {
int ages[10];
printf("ages占用空间大小: %lu\n", sizeof(ages));
printf("10个int类型数据占用空间大小: %lu\n", sizeof(int)*10);
return 0;
}
从结果来看, 数组的大小确实为数据类型的大小×数组的长度